개요
DB의 인덱스 개념이 궁금해 정리했습니다. MySql은 인덱스의 구조도 같이 찾았습니다. 인덱스는 B-tree, B+tree 2가지 구현방식이 있으며, 결론적으로 B+tree 방식이 사용됩니다. 각 특징은 무엇이고 차이점은 무엇인지 확인해 봅시다.
학습 목표
- B-tree와 B+tree의 특징을 알 수 있다
- MySql에서 왜 B+tree가 사용되는지 알 수 있다
B-tree
이진트리는 일반적으로 하나의 노드에 하나의 값, 최대 2개의 자식으로 구성되어 있습니다.
하지만 B-tree는 하나의 노드에 여러 개의 값을 가질 수 있고 최대 자식이 2개 이상 일 수 있습니다
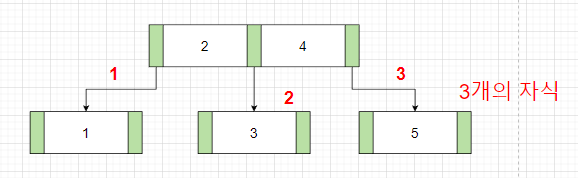
아래 사진처럼, B-tree는 3개의 값, 4개의 자식이 있을 수 있습니다.

하나의 노드의 최대 자식수가 3개이면 3차 B-tree, 4개이면 4차 B-tree라고 합니다.
최대 자식수의 개수에 따라서 1.,2,3,... M차 B-tree가 있습니다.
(m차 B-tree이면 하나의 노드가 가지는 키의 최대개수는 m-1입니다)
노드의 구분
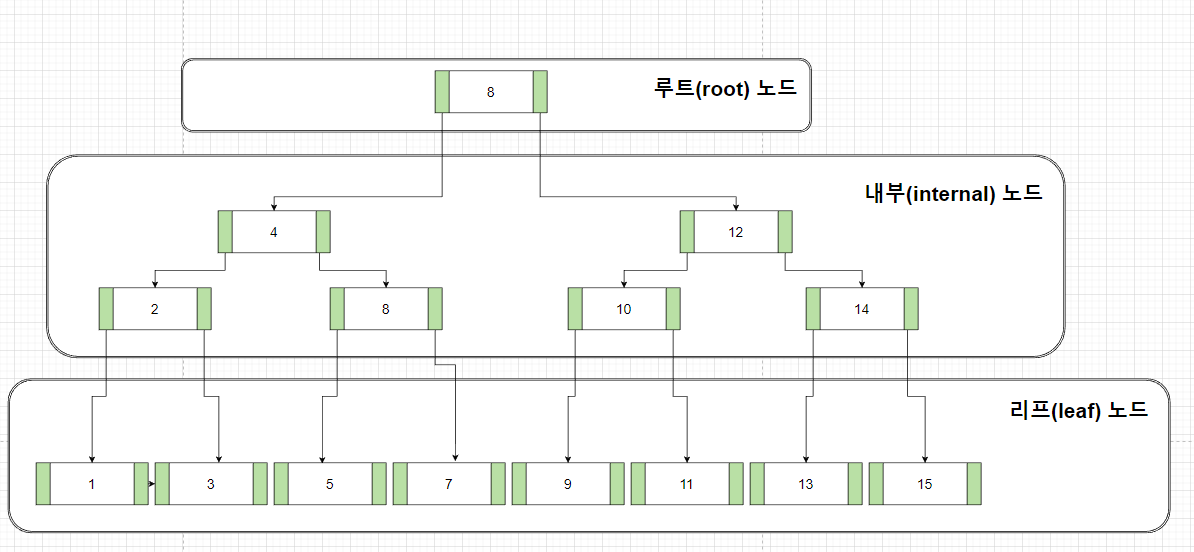
- 루트(root) 노드
최상단에 위치한 노드
- 리프(leaf) 노드
자식이 없는 최하단에 위치한 노드
- 내부(internal) 노드
루트노드와 리프노드를 제외한 모든 노드
B-tree 조건
Knuth에 따르면 B-tree는 다음과 같이 정의할 수 있습니다.
1. Every node has at most m children.
2. Every internal node has at least ⌈m/2⌉ children.
3. Every non-leaf node has at least two children.
4. All leaves appear on the same level and carry no information.
5. A non-leaf node with k children contains k−1 keys.
1. 모든 노드들은 최대 m개의 자식을 가질 수 있습니다.
2. k개의 자식을 가진 리프가 아닌 노드는 k-1개의 키를 가지고 있습니다.
3. 모든 내부 노드는 최소 [m/2]개의 자식을 가져야 합니다
4. 모든 리프 노드들은 같은 레벨에 있어야 합니다
5. 리프가 아닌 모든 노드들은 최소 2개 이상의 자식을 가져야 합니다
(참고로 ⌈m/2⌉ 은 반올림입니다.)
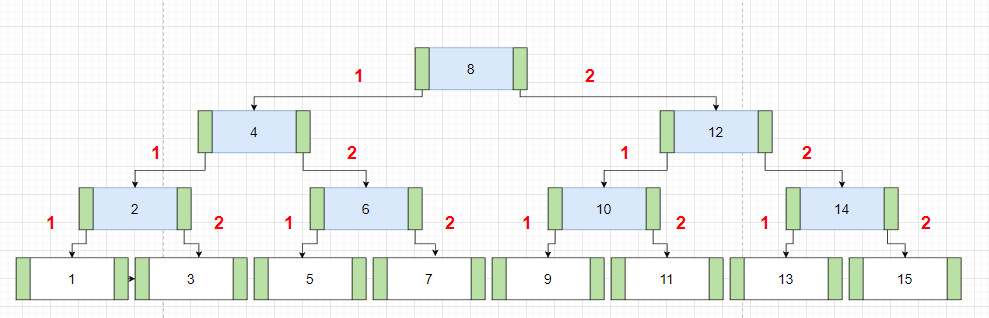
m =3 인 3차 B-tree를 예시로 들겠습니다.
1. 모든 노드들은 최대 m개의 자식을 가질 수 있습니다 (3개)
2. k개의 자식을 가진 리프가 아닌 노드는 k-1개의 키를 가지고 있습니다.
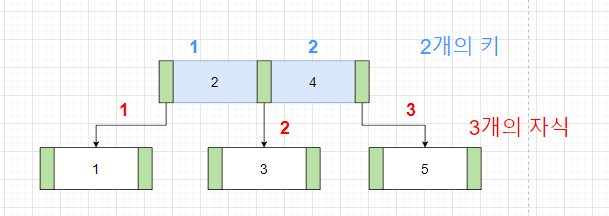
3. 모든 내부 노드는 최소 [m/2]개의 자식을 가져야 합니다 (2개)
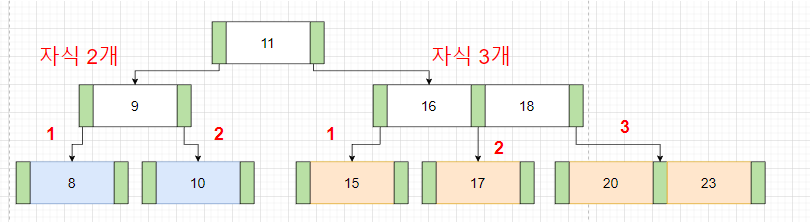
4. 모든 리프 노드들은 같은 레벨에 있어야 합니다
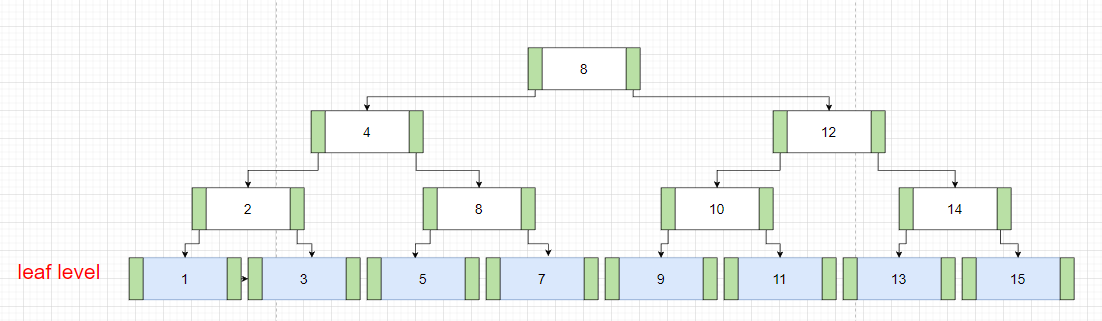
5. 리프가 아닌 모든 노드들은 최소 2개 이상의 자식을 가져야 합니다
B+tree
B-tree를 개선해서 B-tree가 등장했습니다.
가장 큰 2가지 특징은 다음과 같습니다.
- 모든 리프 노드들은 링크드 리스트 형태로 이어져있다.
- 실제 데이터는 리프노드에만 저장된다. 내부노드들은 단지 키만 가지고 있고 올바른 리프 노드로 연결해 주는 라우팅 기능을 한다.
리프 노드들만 d1, d2... d7 데이터를 가집니다. B+tree는 중복 키를 가집니다. 왜냐하면 내부 노드들이 데이터를 가지고 있지 않기 때문에 리프노드들이 키와 데이터를 모두 가지고 있어야 하기 때문입니다. (3,5가 중복 키를 가집니다.)
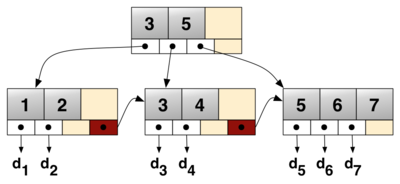
아래 B+tree는 사실상 리프노드의 키들과 그 이외에 키들이 같은 경우입니다.

B+tree는 실제 데이터를 리프 노드에만 저장하므로 B-tree에 비해 같은 노드에 더 많은 키를 저장할 수 있습니다. 데이터를 찾기 위해 리프노드까지 탐색을 해야 하는데 링크드 리스트로 연결되어 있기 full scan 시 리프 노드들만 순차 탐색하면 되기 때문에 탐색에 유리합니다. 반면 B-tree는 모든 노드를 탐색해야 합니다.
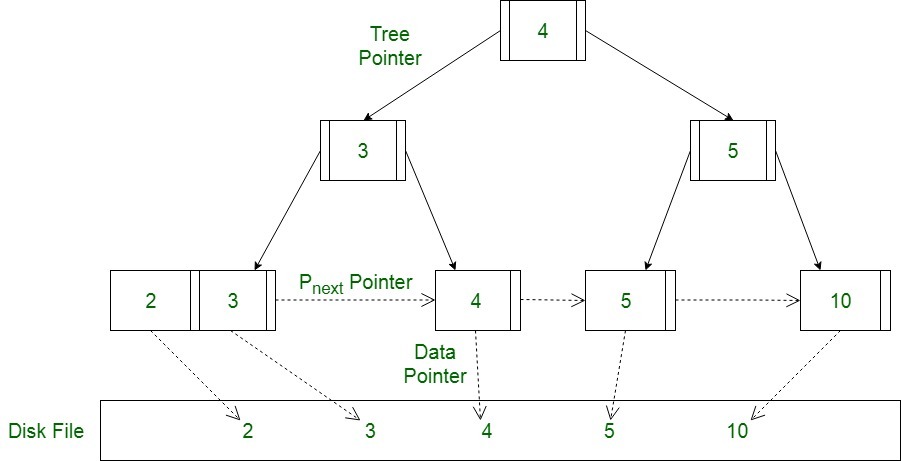
데이터베이스에서의 B-tree
메인 메모리는 주요 저장소로, 제한적인 공간 때문에 모든 데이터를 저장할 수 없습니다. 따라서, 보조 저장소를 사용하는데, 페이지라고 부르는 마그네틱 디스크에 저장해서 비용을 줄입니다.
디스크에서 메모리로 데이터를 전송하기 위해서는 디스크 읽기를 해야 합니다. 비록 페이지에서 하나의 데이터만 조회하고 싶어도, 디스크는 모든 페이지 접근을 수행합니다. 디스크는 메인메모리만큼 빠르지 않은데, 읽기를 할 때마다 찾기와 회전 지연이 있기 때문입니다. 디스크에 접근이 많아질수록, 검색에 필요한 시간은 길어집니다.
DBMS는 B-tree의 인덱싱을 활용해 특정 데이터를 찾기 위한 읽기 작업의 빈도를 낮춥니다. B-tree가 구성되어 있으므로, 각각의 노드는 메모리에서 하나의 페이지를 담당하여 각 노드가 최소한 절반을 채워두도록 하여 읽기 접근의 횟수를 줄입니다.
B-tree와 B+tree의 비교
| B-tree | B+tree | |
| 주요 특징 | 모든 내부, 리프 노드들이 데이터를 가진다 | 단지 리프노드만 데이터를 가진다 |
| 검색 | 모든 키가 리프에서 사용가능 하지 않기 때문에, 검색이 때로 느리다 | 모든 키가 리프 노드에 있기 때문에 검색이 빠르고 정확하다 |
| 중복 키 | 트리에 중복키가 없다 | 중복키가 존재하며 모든 데이터들은 리프에 있다 |
| 삭제 | 내부 노드의 삭제는 목잡하고 트리 변형이 많다 | 어떠한 노드든 리프에 있기 때문에 삭제가 쉽다 |
| 리프노드 | 링크드 리스트로 저장되지 않는다 | 링크드 리스트로 저장된다 |
| 높이 | 특정 갯수의 노드는 높이가 높다 | 같은 노드일 때 B-tree보다 높이가 낮다 |
| 사용 | 데이터베이스, 검색엔진 | 멀티레벨 인덱스, DB 인덱스 |
* 참고
https://www.javatpoint.com/b-plus-tree
https://www.baeldung.com/cs/b-trees-vs-btrees
https://en.wikipedia.org/wiki/B-tree
https://www.cs.usfca.edu/~galles/visualization/BTree.html
https://www.programiz.com/dsa/b-tree
'학습 > DB' 카테고리의 다른 글
| Connection Pool & DataSource (0) | 2022.09.02 |
|---|---|
| JDBC 의 역사 (0) | 2022.09.01 |
| 낙관적 잠금과 비관적 잠금으로 동시성 해결하기 (0) | 2022.08.19 |
| 트랜잭션 격리 수준 (0) | 2022.08.12 |
| 고급매핑 - 상속관계 (0) | 2022.07.07 |



