개요
회사 게시판에서 db 트랜잭션 관련하여 재미있는 글을 봤습니다. 예약 시스템을 만드는데 select로 채번 순서를 가져오고 insert를 하다 보니 중복되는 예약번호가 나오는 문제가 있었고 어떻게 해결했는지를 적은 글이었습니다. 다중 쓰레드의 동시성으로 발생한 문제이며, select 시 동시성 문제를 해결해야 했습니다. 그러면서 트랜잭션 격리 레벨이 궁금해져서 찾아보게 되었습니다.
트랜잭션이란?
트랜잭션이란, 데이터베이스 작업의 논리적 단위입니다.
삽입, 수정, 삭제가 성공적으로 끝나 영구적으로 반영을 할 때 commit을 사용합니다.
삽입, 수정, 삭제의 변경 내용을 취소하고 복구해야 한다면 rollback을 사용합니다.
DBMS는 잠금(Lock) 기능을 사용하며 다른 트랜잭션의 접근을 제어하여 동시성 제어를 합니다.
접근 제어의 방식에 따라 트랜잭션 격리 수준(transaction isolation level)이 다르며 크게 4가지 종류가 있습니다.
이 내용은 아래에서 짚어보겠습니다.
동시성 제어(Concurrency Control)란?
동시성 제어란, 여러 사용자가 있는 DBMS환경에서 여러 트랜잭션의 상호 간섭으로 데이터베이스에 문제가 일어나지 않도록, 트랜잭션의 실행 순서를 제어하는 기법입니다.
동시성 제어는 아래 사진과 같이 동시성과 일관성의 관계에 유의해서 정책을 설정해야 합니다.
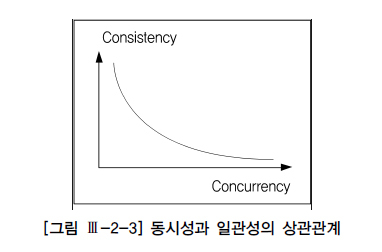
동시성(Concurrency)이란, 다중 사용자가 같은 데이터를 동시에 접근 하는 것입니다.
동시성이 높다면, 많은 사용자가 같은 데이터를 계속 변경할 것이고 일관성이 낮아지게 됩니다.
반대로 동시성이 낮다면, 많은 사용자가 접근하지 않으므로 일관성이 높습니다.
일관성(Consistency)이란, 자신이 발생시킨 변경사항과 다른 트랜잭션의 변경사항을 다중 사용자 각각이 일관된 데이터로 보는 것입니다.
일관성이 높다면, 변경이 많이 발생하지 않는다는 뜻이므로 동시성이 낮아집니다.
반대로 일관성이 낮다면, 변경이 많이 발생한다는 뜻으로 동시성이 높아집니다.
결론적으로, 동시성과 일관성은 서로 반비례하는 관계로 동시성 제어는 굉장히 까다롭습니다.
왜냐하면, 동시성을 높이려고 잠금의 사용을 최소화하면 일관성을 유지하기 어렵고,
일관성을 높이려고 잠금의 사용을 늘리면 동시성을 유지하지 어렵기 때문입니다.
따라서, 동시성과 일관성 두마리 토끼를 잡기 위해서는 굉장히 세심한 주의가 필요합니다.
동시성 제어 이상 현상 3가지
트랜잭션 격리 수준에 따라서 발생할 수 있는 현상(phenomena) 3가지를 알아보겠습니다
Dirt read, Non-Repeatable read, Phantom read 3가지가 있으며 다양한 설명들이 많이 있습니다. 이중에 SQL-92 ANSI라는 표준 개념을 먼저 확인해보겠습니다.
SQL-92 ANSI 설명
1) P1 ("Dirty read"): SQL-transaction T1 modifies a row. SQL- transaction T2 then reads that row before T1 performs a COMMIT. If T1 then performs a ROLLBACK, T2 will have read a row that was never committed and that may thus be considered to have never existed.
2) P2 ("Non-repeatable read"): SQL-transaction T1 reads a row. SQL- transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted.
3) P3 ("Phantom"): SQL-transaction T1 reads the set of rows N that satisfy some <search condition>. SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy the <search condition> used by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same <search condition>, it obtains a different collection of rows.
* 출처
http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
1) Dirty read : 트랜잭션 1(이하 T1)이 SQL 1개의 로우를 변경합니다. 트랜잭션 2(이하 T2)가 T1이 COMMIT 하기 이전에 로우를 읽습니다. 만약에, T1이 ROLLBACK을 수행한다면, T2는 커밋된 적이 없고 결론적으로 존재하지 않는 로우를 읽게 됩니다.
2) Non-repeatable read : T1이 SQL 1개의 로우를 읽습니다. T2가 해당 로우를 변경하거나 삭제하고 COMMIT합니다. 만약에 T1이 다시 해당 로우를 읽으려고 한다면, 그 결과는 변경되거나 삭제되어 확인할 수 없습니다.
3) Phantom read : T1이 어떠한 <조건 검색>을 만족하는 N개의 로우를 읽습니다. T2는 T1때 사용했던 <조건 검색>을 만족하는 N개 이상의 로우를 추가합니다. T1이 같은 <조건 검색>으로 초기의 읽기를 반복한다면, 다른 T2가 추가한 로우까지 읽어 결과가 상이합니다.
동시성 제어가 각 트랜잭션의 데이터의 ACID 성질을 최대한 만족시키기 위한 노력임을 생각했을 때, 같은 트랜잭션 내에서 같은 쿼리문이 다른 결과를 낸다는 것은 엄청난 문제가 될 수 있습니다.
개인적으로 해당 설명에서 Non-repeatable read와 Phantom read 차이에서 주목하는 것은, 로우의 갯수와 조건 검색 여부입니다. 전자의 경우는 1개의 로우를 기준으로 설명하고 있으며, 후자의 경우 N개의 로우와 조건 검색을 기준으로 설명합니다.
트랜잭션 고립 수준에 따라서 각 현상을 허용하는지 안 하는지 달라집니다.
| 고립수준 | Dirty Read | Non-Repeatable Read | Phantom Read |
| Read Uncommited | 허용 | 허용 | 허용 |
| Read Commited | X | 허용 | 허용 |
| Repeatable Read | X | X | 허용 |
| Serialize | X | X | X |
Serialize는 모든 현상을 예방할 수 있지만, 동시성을 극단적으로 막는다는 것에서 안전하지만 성능 문제를 낼 수 있습니다.
Read Uncommitted는 모든 현상이 허용되는만큼 동시성에 자유롭지만, 일관성에 문제가 생겨 사용되지 않습니다.
Wiki 설명
- Dirty read
아직 커밋되지 않은, 다른 트랜잭션이 진행 중인 상태에서 데이터를 읽을 수 있습니다. 이 경우, Dirty 한 데이터 읽기라고 하며, 데이터의 무결성이 깨집니다.
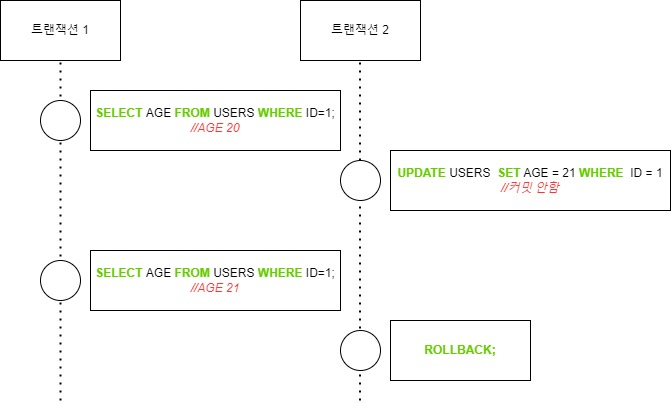
- Non-Repeatable read
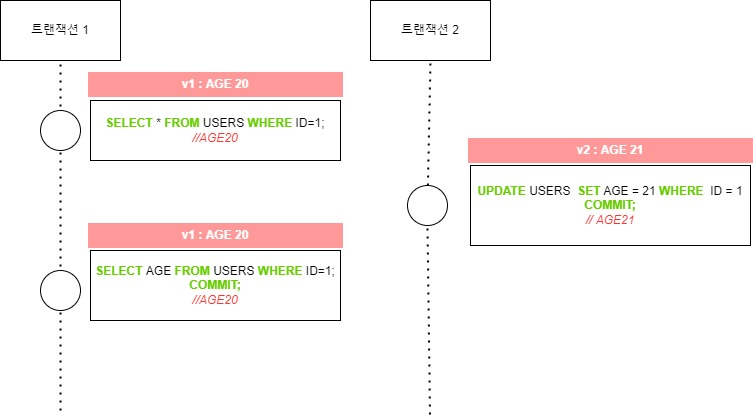
Non-Repeatable read는 시간 T1에서 읽은 데이터를 시간 T2에서 다시 읽을 때 데이터 수정 및 삭제로 결과가 달라지는 현상입니다. SELECT를 하는 동안 읽기 락이 없거나, SELECT가 끝나면 바로 락이 해제되어 발생합니다.
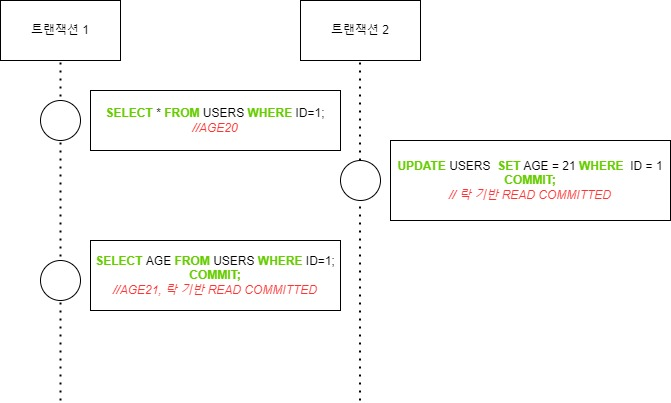
첫번째 해결 방법은 락 기반 동시성 제어(lock-based concurrency control)를 사용하여 트랜잭션 시작과 동시에 COMMIT 혹은 ROLLBACK으로 끝날 때까지 락 잠금을 거는 방법입니다. 트랜잭션 2는 대기하고 있다가 트랜잭션 1이 모두 끝나면 비로소 그때 작업을 시작합니다. 마치 순차적 스케줄처럼 작동하는데, ID = 1 인 데이터에 락 잠금을 걸어 COMMIT 이후에 락 작금을 해제합니다.
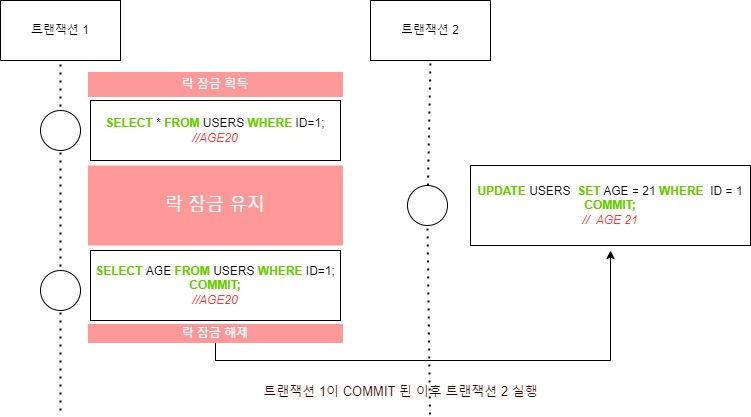
두번째 해결 방법은 다중 버전 동시성 제어(multi-version concurrency control)를 사용하여, 읽기와 쓰기를 별도로 실행하는 방법입니다. 별도로 실행하기 때문에 락 기반보다 성능이 조금 더 좋습니다. 이는 데이터를 작업에 따라서 여러 개의 버전을 만드는 것으로, 데이터의 수정이 필요한 경우, 과거의 데이터를 덮어쓰는 것이 아니라 새로운 버전을 만듭니다. 따라서, 트랜잭션 1에서 시도한 SELECT 2번 모두 같은 버전의 데이터를 읽을 수 있으며, 트랜잭션 2는 동시에 수정을 하여도 서로 영향을 주지 않습니다.
- Phantom read
Phantom read는 Non-Repeatable read의 일종으로, 시간 T1에서 쿼리를 실행하고 시간 T2에서 쿼리를 재실행했는데, 그 사이 T1에 없던 로우가 데이터 베이스에 추가되거나 삭제되어 결과가 달라지는 현상입니다. 이미 읽은 데이터가 변경되는 것이 아니라, 쿼리 조건을 만족하는 데이터가 이전보다 많아지거나 적어지는 현상입니다.
Repeatable read는 특정 스냅샷을 기준으로 트랜잭션을 실행하지만 조건 범위가 있는 SELECT문에는 적용되지 않습니다. 아래는 트랜잭션 1에서 AGE가 10~30 사이인 데이터를 SELECT 했는데, 트랜잭션 2에서 AGE가 27인 데이터를 삽입하고 있습니다.
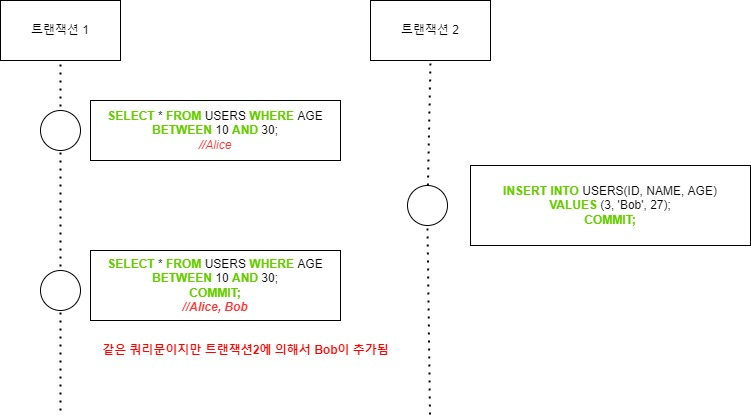
해결책은 Serialize를 이용하는 것입니다.
락 기반 동시성 제어에서는, 범위가 있는 SELECT에 락을 획득합니다. Repeatable Read에서 범위 락(range lock)이 없기 때문에 문제가 발생했지만, Serialize에는 범위 락이 있으므로 Phantom Read를 해결할 수 있습니다.
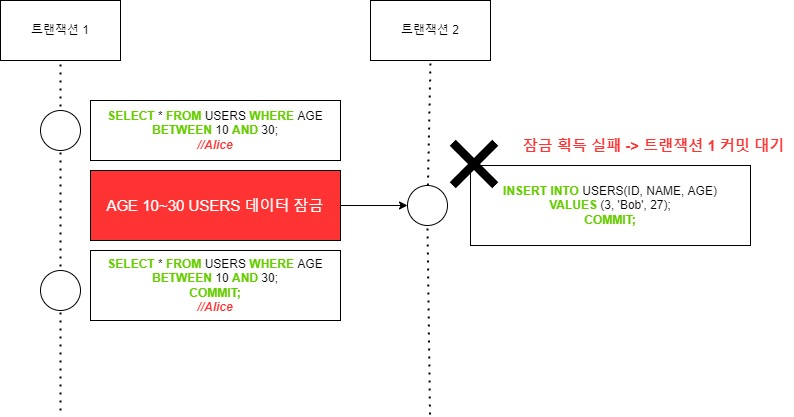
락 기반 동시성 제어가 아닌 경우, 어떠한 락도 획득되지 않지만, 동시에 여러 트랜잭션 작업으로 쓰기 충돌이 감지되면, 트랜잭션들 중에 하나만 커밋에 성공합니다.
트랜잭션 고립 수준 4가지
- Read Uncommited
Read Uncommited는 Dirty read가 발생하며 커밋되지 않은 데이터를 덮어쓰는 Dirty write도 발생할 수 있습니다. 데이터 일관성을 심각하게 해치기 때문에 이 수준을 사용하는 경우는 거의 없습니다.
- Read Commited
Read Commited는 Read Uncommited와 달리 커밋된 데이터만 읽을 수 있습니다. 또한 커밋된 데이터만 덮어쓸 수 있습니다. 커밋된 값과 트랜잭션 진행 중인 값이 따로 보관됩니다. 행 단위 잠금을 사용하여 같은 데이터를 수정한 트랜잭션의 작업이 끝날 때까지 대기합니다.
Dirty read는 해결했지만, Non-Repeatable Read가 발생합니다. 시간 T1, T2 사이에 다른 트랜잭션이 수정 및 추가, 제거를 한 경우 읽는 "시점"에 따라서 데이터의 값이 달라질 수 있습니다.
Read Committed는 오라클의 기본 정책으로, 오라클 이외에 타 데이터베이스는 데이터를 읽을 때 Lock이 걸려 대기해야 합니다. 오라클은 DML 데이터를 읽을 때, Lock이 아닌 언두(Undo) 방식을 활용합니다.
하지만 아래 오라클 공식문서에 나온 것처럼 non-repeatable read와 phantom read 현상에 주의해야 합니다.

- 언두(Undo) 영역이란?
언두 영역은 UPDATE, DELETE 같은 데이터 변경을 할 때 변경되기 직전의 데이터를 보관하는 장소입니다.
보통 DB는 Read Committed를 기본 모드로 채택하는데, Oracle의 경우 Lock을 사용하지 않고 쿼리 시작 시점에 언두 영역 데이터를 제공하는 방식으로 구현합니다.
만약 member 테이블에 name이 홍길동인 로우가 존재한다고 가정하고 아래와 같이 수정해보겠습니다.
UPDATE member SET name = '백엔드' WHERE member_id='5';
UPDATE문 작업 바로 직전에 이전 name인 '홍길동'이 언두 영역에 저장됩니다. 따라서 UPDATE문이 아직 COMMIT이 안되었다면, 다른 트랜잭션은 언두 영역을 조회합니다. UPDATE문이 COMMIT을 안하고 ROLLBACK을 하면, 언두 영역을 활용해서 바로 데이터를 복구합니다.
- Repeatable Read
Repeatable Read는 같은 트랜잭션에 있으면 같은 데이터를 읽습니다. 시간 T1에서 쿼리를 실행하는 중에 다른 트랜잭션이 데이터를 변경하더라도, 같은 트랜잭션에 있는 내용은 스냅샷 형식으로 저장되어 있기 때문에 시간 T2에서 읽은 데이터는 T1에서와 동일한 시점입니다.
Non-Repeatable Read를 해결했지만, Phantom Read가 발생합니다. 새로운 데이터가 '추가' 된다면, 트랜잭션 내에서 범위 조회 시, 예상하지 못한 추가된 데이터를 같이 읽게 됩니다.
또한 수정 시, Lost Update가 발생합니다. 같은 데이터를 동시에 수정할 때, 일부 수정이 유실됩니다. 조회 수 증가, 위키 페이지 수정 등의 경우가 있습니다. 예를 들어 조회수가 1인 게시물을 2명이 동시에 조회한다면, 각각 1씩 증가해서 3이 되어야 하지만, 2명 모두 조회수를 2로 업데이트하여 1개의 조회 수가 유실될 수 있습니다.
해결책은 원자적 연산(cnt = cnt + 1), 낙관적 잠금, 비관적 잠금 CAS(버전 비교) 등이 있습니다.
오라클을 제외한 대부분의 데이터베이스가 로우 단위의 공유 읽기 락을 사용해서 해당 정책을 구현합니다. 이로 인해, 데드락과 같은 교착 상태가 발생될 수 있습니다. 오라클에서 명시적으로 지원하지는 않지만, for update 절을 이용해 구현 가능합니다.
- Serialize
Serialize는 인덱스 잠금이나 조건 기반 잠금을 사용합니다. select를 한 순간, 어떠한 트랜잭션에서도 접근을 못하게 막습니다. 일관성을 유지시킬 수 있는 가장 강력한 방식이지만, Lock을 최대한으로 사용하기 때문에 동시성이 떨어져 성능에 문제가 발생할 수 있습니다.
* 참고
'학습 > DB' 카테고리의 다른 글
| DB의 인덱스와 B-tree, B+tree (0) | 2022.08.24 |
|---|---|
| 낙관적 잠금과 비관적 잠금으로 동시성 해결하기 (0) | 2022.08.19 |
| 고급매핑 - 상속관계 (0) | 2022.07.07 |
| JDBC란? (0) | 2022.07.05 |
| HikariCP란? (0) | 2022.07.04 |



