cache란?
캐시란, 나중에 요청될 결과를 미리 저장해두었다가 빠르게 서비스를 해주는 것을 의미합니다. 예를 들어 Factorial의 Dynamic programming이 있습니다. 미리 계산을 해두면 나중에 계산을 또 하지 않아도 됩니다. 4! = 4 * 3!입니다. 3!은 3! = 3 * 2!입니다. 이렇게 3!을 미리 저장해두고 4!에 이용하면 빠르게 계산 할 수 있습니다.
캐싱 전략(Caching Strategy)
캐싱전략은 크게 Look aside Cache와 Write Back 2가지 방식이 있습니다. 또한 Write에는 Cache 데이터 저장 여부에 따라 Write-Around, Write-Through 2가지가 있습니다.
1. Look aside Cache(Lazy Loading)
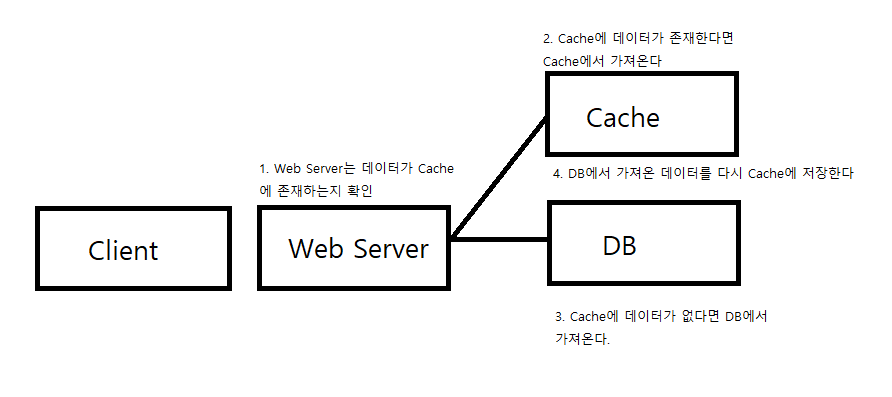
이 구조의 장점은, Cache에 데이터가 저장되어 있다면, DB에 접근하는 대신 Cache에서 호출함으로써 부하를 줄일 수 있습니다. Redis가 다운되더라도 바로 장애로 이어지지 않고 DB에서 데이터를 가지고 올 수 있습니다.
하지만, Redis가 다운이 된다면, Cache로 붙어있던 많은 커넥션이 DB에 갑자기 몰려서 과부하를 줄 수 있습니다. 따라서 새로운 데이터들이 DB에만 몰리게 되어, Cache Miss가 발생할 수 있습니다. 해결책으로 새로운 Cache를 넣어주거나, 미리 DB에서 Cache에 강제로 데이터를 밀어넣는 Cache Warmup 전략을 사용합니다. 실제로 티켓링크에서 티켓 오픈 전에, 상품 DB 데이터를 Cache에 밀어넣습니다.
2. Write Back

Write Back은, 쓰기가 굉장히 빈번할 때 사용하며, DB(Disk)에 바로 저장하지 않고 Cache에 먼저 저장합니다. 그리고 특정 시점에 Cache 데이터를 DB에 저장합니다. 매초 일어나던 행위를 매분, 매분 일어나던 행위를 매시간 단위로 바꿀 수 있어 부하가 줄어듭니다.
단점은 캐시에 먼저 저장하므로 장애가 생기면 모든 데이터가 사라집니다. 극단적으로 heavy한 데이터, 재생 가능한 데이터의 경우 캐쉬를 사용하면 좋습니다. 특히, 로그를 DB에 저장할 때 많이 사용합니다.
또한 Write시에도 경우에 따라 2가지 방법이 있습니다.
1. Write-Around

Write-Around는 Cache를 거치지 않고 무조건 DB에 저장합니다.(캐싱을 갱신하지 않습니다.) 그리고 조회 시, cache miss의 경우에만 DB에서 데이터를 가지고 와서 조회합니다. 저장을 할때는 한번만 저장해서 간단하지만, 단점은 Cache 데이터와 DB 데이터가 맞지 않을 수 있습니다.
2. Write-Through
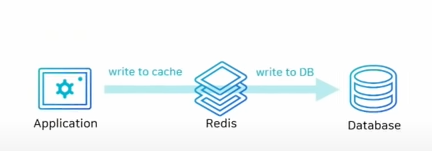
Write-Through는 DB에 데이터를 저장할 떄 Cache에도 같이 저장하는 것입니다. 장점으로 Cache는 항상 최신의 데이터를 가지고 있지만, 저장을 2번 한다는 점에서 상대적으로 느리다고 볼 수 있습니다. 그리고 저장되어도 사용하지 않는 데이터가 있을 수 있으므로 리소스 낭비입니다. 이럴 때는, 일정 시간만 보관하겠다는 expire time을 설정해 주어야 합니다.
cache를 활용하는 경우는?
- 랭킹 시스템
DB에 유저의 Score를 저장하고 sort by로 조회하는데, 개수가 많아지면 속도에 문제가 생깁니다. 그래서, In-Memory 기준으로 랭킹 서버의 구현이 필요합니다. 예를 들어, Redis의 Sorted Set을 이용하면, 랭킹을 손쉽게 구현할 수 있습니다.(Replication도 가능합니다.)
Redis는 Collection을 왜 사용할까?
Redis의 경우 Memcached와는 달리 다양한 컬렉션(Collection)을 사용합니다. Redis의 컬렉션은 원자성을 보장(Atomic)하기 때문에 자원 경쟁을 피할 수 있어 트랜잭션 경합의 영향을 덜 받습니다. 또한 싱글 스레드이므로 쓰레드 안전하여 멀티 쓰레드 이슈가 적습니다.
캐시 저장소로 사용되는 Redis는 또한 인증토큰 저장(string, hash), ranking 보드(Sorted set), 유저 API Limit, 잡 큐(list)
등에 사용됩니다.
Redis Collection 주의사항
하나의 Collection에 너무 많은 아이템을 담으면 좋지 않습니다. 10000개 이하 및 몇천개 수준을 유지해야 쾌적하게 이용 가능합니다. 하나의 Redis에서 몇만개를 운영하는 것보다 여러개로 나눠서 몇천개씩 유지하는게 좋습니다.
Expire는 Collection 아이템 개별로 걸리지 않고, 전체 Collection에 대해서 걸리니다. 즉 해당 10000개의 아이템을 가진 Collection에 expire가 걸려 있다면, 그 시간 후에 10000개의 아이템이 모두 삭제되므로 주의해야 합니다.
Redis 자료구조의 종류는 다음과 같습니다.
| 자료구조 종류 | 예시 | 특징 |
| Strings | I am a student | 제일 기본적인 문자열 타입, Set 형태로 저장하는 경우 모두 String 형태이다. |
| Bitmaps | 10100011010011001010101 | bit 단위의 연산이 가능하다, 데이터 저장공간을 절약한다. |
| Lists | { A -> B -> C -> D } | 데이터를 순서대로 저장하므로 Queue로 사용하기 적절하다. Event Queue로 사용한다. |
| Hashses | {"Name" : "GARIM", "Age" : "27"} | 여러개의 key와 value쌍으로 데이터를 저장한다. |
| Set | {A, B, C, D, E, F} | 중복되지 않은 문자열의 집합이다. |
| Sorted Set | {"LG": 1, "KT" :2, "SSG": 3} | 중복되지 않은 값을 저장하지만 score라는 순서로 정렬된다. |
| HyperLogLogs | 00110101 110011110 | 굉장히 많은 데이터를 다룰 때 쓰고, 중복되지 않은 값의 갯수를 셀 떄 사용한다. |
| Streams | {"ID":153434325326", {"f1:"v1","f2":"v2"}} | log를 저장하기 가장 좋은 자료형이다. set과 비슷하지만 저장되는 용량이 매우 작다(12KB 고정) |
스프링 캐싱 어노테이션 종류 및 개념
스프링에서 캐시 관련 명령어로 @ Cacheable, @CacheEvict, @CachePut, @Caching 4가지를 알아보겠습니다.
@Cacheable: 캐시 채우기
@Cacheable("addresses")
public String getAddress(Customer customer) {...}
getAddress() 호출은 메서드가 동작하기 전에 처음에 cache를 확인합니다. cache에 없다면 메서드가 호출되고 캐시에 저장합니다. 캐시는 하나 뿐마 아니라 복수개를 호출 할 수 있습니다.
@Cacheable({"addresses", "directory"})
public String getAddress(Customer customer) {...}
@CacheEvict: 캐시 제거
모든 메서드를 @Cacheable로 만들면 사이즈에 문제가 생깁니다. 필요하지 않은 것은 적절하게 삭제해주어야 합니다.
@CacheEvict 어노테이션으로 value를 삭제해서 새로운 value가 캐시에 저장될 수 있도록 합니다.
@CacheEvict(value="addresses", allEntries=true)
public String getAddress(Customer customer) {...}
비울 캐시와 함께 allEntries 추가 매개변수를 사용합니다. 이렇게 하면 캐시 주소의 모든 항목이 지울 수 있습니다..
@CachePut: 캐시 업데이트
@CacheEvict는 사용하지 않은 캐시들을 삭제해서 부하를 줄일 수 있지만, 반대로 너무 많은 삭제는 원하지 않습니다.
대신에, @CachePut을 이용해 캐시를 업데이트 할 수 있습니다.
@CachePut(value="addresses")
public String getAddress(Customer customer) {...}
@Cacheable은 메서드 실행을 생략할 수 있는 반면, @CachePut은 메서드를 항상 실행합니다.
@Caching: 캐시 그룹화
같은 종류의 캐시 메서드를 사용하고 싶을 때, @Caching 메서드를 사용합니다.
@Caching(evict = {
@CacheEvict("addresses"),
@CacheEvict(value="directory", key="#customer.name") })
public String getAddress(Customer customer) {...}
@Caching을 통해서 @CacheEvict 여러개를 그룹화 할 수 있습니다.
* condition으로 input 조건 설정하기
@CachePut(value="addresses", condition="#customer.name=='Tom'")
public String getAddress(Customer customer) {...}
어노테이션이 작동할 때 좀 더 설정을 하고 싶다면 ,condition에 SpEL 표현식을 사용 할 수 있습니다.
* unless로 output 조건 설정하기
unless를 통해 input이 아닌 output을 기반으로 캐싱을 관리할 수 있습니다.
@CachePut(value="addresses", unless="#result.length()<64")
public String getAddress(Customer customer) {...}
위의 어노테이션은 만약에 result의 길이가 64보다 적으면 캐시 업데이트를 합니다. 즉, 결과를 보고 판단합니다.
condition과 unless 모두 어떠한 캐시어노테이션에서 사용할 수 있습니다.
Redis cache를 Spring에서 사용하기
이제, 프로젝트에서 Redis를 이용한 cache를 적용하기 위해서 고민했습니다. 사람들이 자주 사용하여 빈번한 요청이 오는 경우가 어딘지, 쓰기보다는 조회가 많을 곳이 어디인지 생각해보았습니다. 그리고, 스터디 게시판 조회를 캐싱하기로 결정했습니다. 사람들이 스터디를 찾기 위해 게시판을 많이 이용할텐대, 그 조회 정보를 캐시를 통해 제공한다면, 빠른 응답속도를 보일 것으로 기대했습니다.
@Cacheable("books")
public Book findBook(ISBN isbn) {...}
gradle에 아래와 같이 의존성을 설정합니다.
implementation 'org.springframework.session:spring-session-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'
application.yml에는 다음과 같이 host, port를 설정합니다. 로컬에 있는 레디스를 구동하기 때문에 localhost를 사용합니다.

- App.java
@EnableCaching
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
캐시 사용을 명시하는 @EnableCaching을 App 에 추가합니다. @EnableCaching은 public 메서드에서 캐싱 어노테이션이 존재하는지 모든 스프링 빈을 검사하는 후처리를 제공합니다. 만약 관련된 어노테이션이 있다면, 자동적으로 메서드 호출을 인터셉트하는 프록시가 생성되고 캐싱을 처리합니다.
- RedisConfig.java
@Configuration
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 1800)
public class RedisConfig {
private final ObjectMapper objectMapper;
public RedisConfig(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration redisStandaloneConfiguration =
new RedisStandaloneConfiguration();
return new LettuceConnectionFactory(redisStandaloneConfiguration);
}
@Bean
public RedisCacheManager redisCacheManager() {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.disableCachingNullValues()
.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper))
);
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>();
redisCacheConfigurationMap.put("Studies",
redisCacheConfiguration.entryTtl(Duration.ofMinutes(5)));
return RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory())
.cacheDefaults(redisCacheConfiguration)
.withInitialCacheConfigurations(redisCacheConfigurationMap)
.build();
}
}
gradle에서 starter-cache 의존성과 @EnableCaching을 통해 RedisCacheManager가 기본 설정으로 만들어지지만, 상세한 동작을 위해 구현하여 사용합니다. RedisCacheConfiguration으로 레디스 캐시 설정을 커스터마이징합니다.
defaultCacheConfig(): 만료시간 없이, null value, prefix key를 허용하고 캐시 이름으로 prefix를 설정합니다.
disableCachingNullValues(): null value를 방지하도록 하며, null인 경우 저장이 되지 않습니다.
serializeValueWith(): Serialize의 기본 JdkSerializationRedisSerializer(serialize data to objects)에서 GenericJackson2JsonRedisSerializer(serialize data into json) 사용하도록 합니다. json 형태를 이용하기 위해서 변경했습니다. 레디스 직렬화 종류 및 장단점은 다음 글을 확인합니다. ( Redis 직렬화 장단점 )
redisCacheConfigurationMap에 해당 레디스 설정을 담으며, 게시글 조회에 사용할 캐쉬 이름은 Studies입니다. 특히, 해당 캐쉬는 5분동안 유지되도록 합니다.
리턴형은 RedisCacheManager.RedisCacheManagerBuilder로 합니다. fromConnectionFactory()에 Lettuce기반으로 커넥션을 사용하도록 하고, cacheDefaults()와 withInitialCacheConfigurations()에 정의한 내용들을 채워넣습니다.
이제, 설치한 Redis와 Spring은 연동이 되었고, 캐시 초기 설정 및, 캐쉬 이름과 TTL을 설정했습니다.
캐시 추상화는 자바 메서드에 적용되어, 캐시에서 사용가능한 정보가 있다면 실행 횟수를 줄입니다. 대상 메서드가 호출될 때마다, 추상화는 메서드가 이미 해당 매개변수로 이미 호출되었는지 확인합니다. 만약에 호출되었다며느 캐시 결과는 실제 메서드 실행 없이 반환합니다. 만약, 메서드가 호출되지 않았다면, 실행이 되고 결과는 캐시에 저장합니다. 이 방법으로 연산이 많은 메서드를 매번 실행시킬 필요 없이 재사용하여 한번만 실행될 수 있도록 합니다.
또한, 캐시 추상화는 모든 내용을 삭제하거나, 수정하는 기능을 제공합니다. 캐시가 어플리케이션의 작동 동안에 데이터를 바꿀 수 있습니다. 스프링에서 다른 서비스와 마찬가지로 캐시 서비스는 추상화를 사용하며, 캐시 데이터를 실제로 저장할 저장소가 필요합니다. 추상화를 통해 캐싱 논리를 작성할 일은 없지만, 실제 저장소를 제공하지는 않습니다. 이 추상화는 보통, Cache와 CacheManager 인터페이스로 구현됩니다.
스터디 게시글에 캐싱 설정하기
스터디 게시판의 페이지별로 스터디 리스트를 캐시로 만들었습니다.
- @Cacheable 설정
@Cacheable(cacheNames = "Studies", key = "#studyState.code + #pageable.pageNumber")
public List<StudyApiDto.StudyResultDto> getStudiesBySearch(
String keyword, StudyState studyState, Account account, Pageable pageable
) {
스터디 조회에 캐시 조회를 활성화합니다. cacheNames는 RedisConfig.java에서 설정했던 이름인 Studies입니다. key는 단순히 스터디 상태 뿐만 아니라, 각 페이지 별로 캐쉬를 하기 위해서 페이지 번호도 추가했습니다. StudyState는 ENUM형태이기 때문에, String형을 사용하기 위해서 studyState.code를 사용했으며, 페이지 번호는 Pageable 안에 있는 peageble.pageNumber를 사용했습니다.
- @CacheEvict 설정
@CacheEvict(cacheNames = "Studies", allEntries = true)
public StudyApiDto.StudyResultDto deleteStudy(String email, Long id) {
스터디 삭제입니다. 스터디가 삭제되는 경우, 캐시 정보를 초기화합니다.
@CacheEvict(cacheNames = "Studies", allEntries = true)
public StudyApiDto.StudyResultDto createStudy(
String email, StudyApiDto.StudyCreateDto studyCreateDto
) {
스터디 생성입니다. 스터디가 생성되는 경우, 캐시 정보를 초기화합니다.
- Postman으로 시간(ms) 테스트 하기

이제, 스터디 게시글을 검색할 때, 캐시가 위와 같이 생성됩니다. Studies는 cacheNames이고, OPEN1은 key로 설정한 값입니다. 스터디 모집중인 OPEN과 2 페이지가 합쳐져서 OPEN1입니다.



- 결과
| 1 | 2 | 3 | 4 | 5 | 평균 | |
| 캐시 적용X | 967ms | 851ms | 909ms | 856ms | 874ms | 891.4ms |
| 캐시 적용O | 1071ms | 319ms | 260ms | 282ms | 236ms | 433.6ms |
처음 조회는 캐시에 상관없이 비슷하지만, 두번째부터 차이를 보입니다. 캐시를 적용한 경우, 같은 요청에 대해서 캐시를 통해서 조회하기 때문에 DB에 접근하지 않아 속도가 높아졌습니다. 이번 실험을 통해, 약 2배정도의 성능 차이가 나는 것을 확인했습니다.
참고
https://brunch.co.kr/@springboot/598
[우아한테크세미나] 191121 우아한레디스 by 강대명님
'문제 해결, 기술 비교 > 개인프로젝트(북클럽)' 카테고리의 다른 글
| RabbitMQ와 Kafka 비교하기 (1) | 2022.06.25 |
|---|---|
| In-memory Redis vs Memcached 비교하기 (0) | 2022.06.21 |
| Redis를 로그인 Session Storage로 이용하기 (0) | 2022.06.17 |
| 분산 서버에서 Session 관리하기 (0) | 2022.06.17 |
| sentry.io로 에러 로그 관리하기 (0) | 2022.06.01 |



