분산서버에서 로그인 관련 Session을 어떻게 관리할지 생각해봅니다. 일단 Load Balancer를 통해, 여러명의 사용자가 여러대의 서버에 요청을 보낸다고 가정합니다.
가장 기초의 Load Balancer
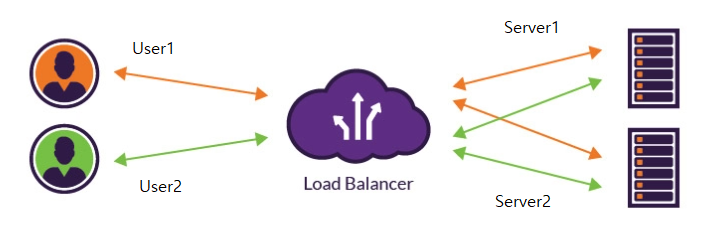
Load Balancer를 사용한 일반적인 서버 관리의 경우 다음처럼 round-robin(기본설정) 알고리즘으로 서버에 요청이 갑니다.
User1과 User2의 요청이 Load Balancer를 거치면, Server1, Server2에 다양하게 라우팅 됩니다.
하지만, 이렇게 다양한 SERVER로 로드 밸런싱이 된다면 다음과 같은 문제에 직면합니다.
1. User1이 Server1에 요청을 보내어 로그인을 합니다.
2. User1이 Server1에서 웹 사이트를 이용합니다.
3. 잠시 후 ser1의 요청이 Load Balancer를 통해 server2로 요청이 갑니다.
4. 로그인이 되어있지 않다는 오류와 함께 다시 로그인을 해야 합니다.
그렇다면 어떻게 User1은 어떠한 요청이든지 간에 로그인을 계속 유지 할 수 있을까요?
Sticky Session
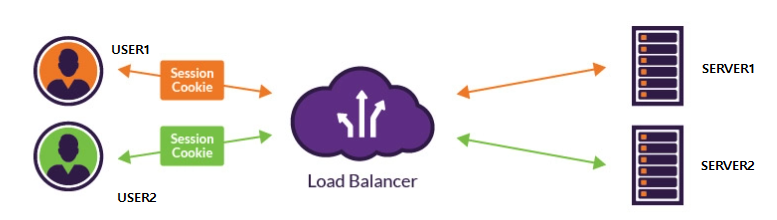
Sticky Session을 사용하여, 특정 클라이언트의 모든 요청을 Load Blanacer에 의해 특정 서버에 라우팅하도록 설정할 수 있습니다. 예를 들어, User1의 IP주소와 정보를 이용해 Server1에만 요청을 보내도록 설정하면, 어느 상황에서든지 User1이 감지되면 Server1으로 요청을 보냅니다. 따라서 불필요한 로그인 시도를 하지 않을 수 있습니다. Sticky Session을 사용하면서 다음과 같은 장단점이 있습니다.
- 장점
- 다른 WAS에 새로운 세션을 만들 필요 없이 한 곳에서 재사용해서 사용할 수 있다.
- 세션 정보 변경을 최소화하여 어플리케이션 성능을 향상시킬 수 있다.
- RAM 캐시 전략을 더 효율적으로 사용하여 서버 반응속도를 올릴 수 있다.
- 단점
- 특정 서버에만 라우팅되도록 설정된다면, 서버에 과부하가 걸리고 성능이 떨어지게 된다.
- 만약 라우팅 되도록 설정된 서버가 죽어버린다면, 결국 다른 WAS에 세션이 생성된다.
잘 이용한다면 충분히 장점이 될 수 있겠지만, 서버가 죽는 경우 수많은 클라이언트의 세션 정보들을 이용 할 수 없다는 점에서 치명적입니다.
Clustering
클러스터링은 Tomcat의 공식문서에 나와있는 방식을 기준으로 설명하겠습니다.

Clustering이란, 한국말로 군집화라고 하며, 모든 서버에 있는 Session의 정보들을 공유하여 관리하는 것입니다.
Tomat에서는 여러개의 서버에서 Clustering 하는 전략을 제공합니다. 크게 2개 종류로 나눌 수 있습니다.
Tomcat can perform an all-to-all replication of session state using the DeltaManager or perform backup replication to only one node using the BackupManager. The all-to-all replication is an algorithm that is only efficient when the clusters are small. For larger clusters, you should use the BackupManager to use a primary-secondary session replication strategy where the session will only be stored at one backup node.
*출처 : (https://tomcat.apache.org/tomcat-9.0-doc/cluster-howto.html)
정리하자면, Tomcat은 DeltaManager를 사용한 all-to-all 세션 복제 방법이 있고, BackupManager를 사용해서 하나의 노드에 복제하는 backup 복제 방법이 있습니다.
all-to-all 복제는 클러스터가 적을 때 효율적입니다. 클러스터의 수가 많다면 BackupManager를 사용해서 primary-secondary 세션 복제를 사용하도록 권고 합니다. (하나의 백업 노드에만 세션을 저장하는 전략)
* apachecon 연도별 정리
https://people.apache.org/~isapir/mockups/tomcat-site/presentations.html
*2018년 Tomcat Clustering(Keiichi Fujino)
https://feathercast.apache.org/2018/09/26/deep-dive-into-tomcat-clustering-keiichi-fujino/
http://events17.linuxfoundation.org/sites/events/files/slides/TomcatCluster_0.pdf
all-to-all session
all-to-all 방식은 모든 세션들이 같은 클러스터 안에 있는 다른 노드들에게도 모두 복제되는 방식입니다. 이는 4개 이하의 클러스터 내에서 권고됩니다. 왜냐하면, 너무 많은 클러스터와 서버가 있으면, 그만큼 세션이 공유되는 과정에서 과부하가 생기기 때문입니다. 또한 DeltaManager를 사용한다면, Tomcat은 어플리케이션이 배포되지 않은 노드들에게도 모두 세션을 공유합니다.

위 사진에서 Primay의 세션 정보들이 다른 Tomat에 전파합니다.
primary-secondary session
primary-secondary 방식은 세션 정보들을 하나의 백업 노드에만 복제합니다.(BackupManager을 사용합니다.) 아무리 많은 노드의 숫자가 늘어나더라도 하나의 노드에만 백업을 하므로 과부하의 걱정이 없습니다. DeltaManager를 사용하다가 후에 클러스터의 노드갯수가 더 많아질 때 BackupManager로 전환을 고려해보아야 합니다.
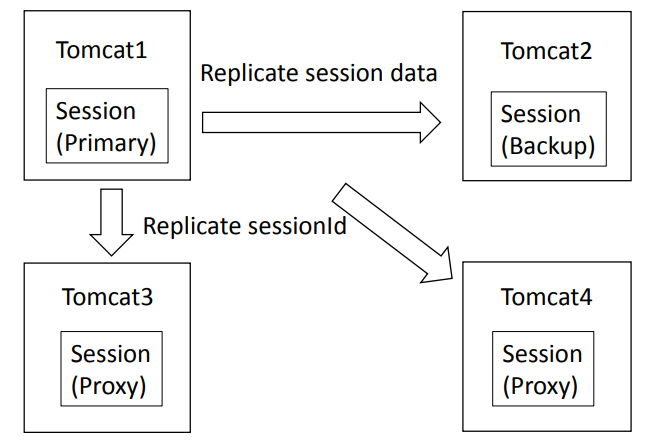
Tomcat1이 Primary이며, Tomcat2는 Backup입니다. Tomcat2가 primary-secondary의 핵심이 되는 백업 노드입니다.
나머지는 모두 Proxy가 되며, sessionId를 복제해서 정보를 보관합니다. Tomcat3와 Tomcat4에는 Session정보가 하나도 없으며, 단지 sessionId만 가집니다. 또한 Pirmay와 Backup 노드는 각각 1개가 정해졌고 모든 세션들이 Tomcat1에서 처리되기 때문에 무조건 Sticky Session을 사용하게 됩니다.

세션을 제거한다면, Primay인 Tomcat1이 모든 Tomcat에세 session 제거를 명령합니다.
* 2014년 Apache Tomcat Clustering(Mark Thomas)
https://www.youtube.com/watch?v=rX1zm11AXcA
위 영상은 2014년 ApacheCon에서 Apache Tomcat Clustering 라는 주제로 발표한 영상입니다. Clustering과 Sticky Session에 대해 정리하고 있습니다.
primary-secondary session에 관해서 backup node가 1개가 아니라고 강조합니다. 2018년 Keiichi Fujino의 발표자료나, 기타 많은 블로그에서는 backup node가 1개라고 설명하고 있습니다. 하지만 2014, 2017년 모두 발표를 한 Mark Thomas는 backup node가 여러 node에 생긴다고 말하며 노드가 죽었을 때 어떻게 다른 노드들이 반응하는지 설명합니다.
(이것이 위 사진에서 1개는 백업 세션을 가지고 나머지는 백업 세션 아이디만 가진다는 설명과 큰 범주에서 같은지는 잘 모르겠습니다.)
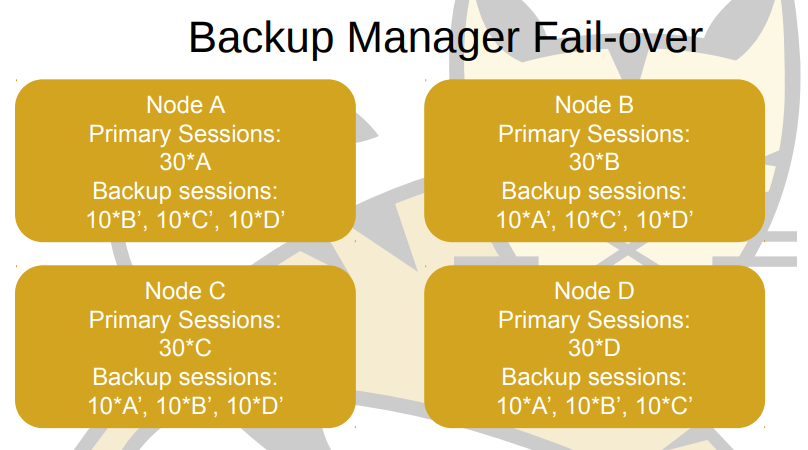
노드 A는 Primary Session로 A 30개, Backup Session으로 B,C,D를 각각 10개를 가집니다. 다른 노드들도 모든 노드들은 Primary Session, Backup Session을 각각 가지고 있습니다.

노드 D가 죽는다면 어떻게 될까요? 위에 설명한 기존 이론에 따르면 하나의 Backup 노드에 복사가 되어 있어야 하는데, Mark Thomas에 따르면 다르게 동작합니다.
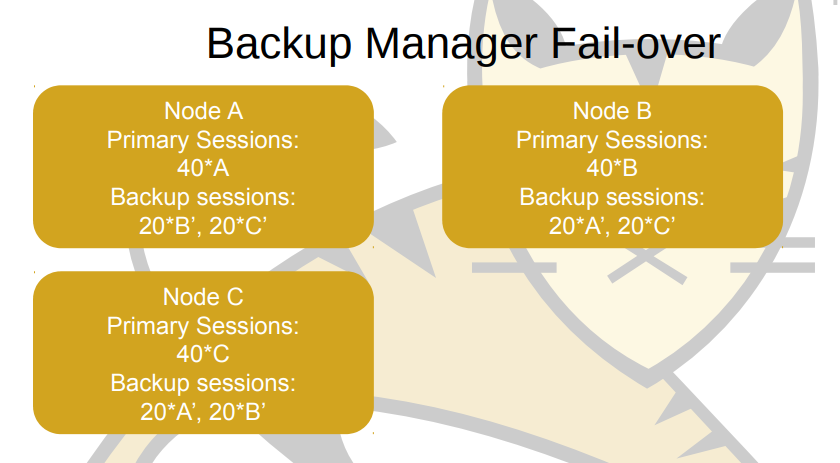
노드가 죽는 즉시, 다른 노드들은 이를 감지하고 조치합니다. Node A,B,C에서 Back Session에 있던 10개의 노드 D가 Primary Session으로 변경됩니다. 왜냐하면 D의 Primary Node가 사라졌기 때문입니다. 이후에, Primary Session들은 다시 Backup Node들을 복사하고 다른 노드들에 추가합니다.
즉, Node A, B, C에 Primary Session이 40개가 된 것은, Node D의 Primary Session 30개가 없어졌기 때문에, 각각 가지고 있던 Backup Session 10개가 Primary로 바뀐 것입니다.
또한, Node A기준으로 봤을 때, Node B, C 2개의 Primary Session이 10개씩 총 20개가 늘어났기 때문에, 복제본인 Backup Session도 20개로 늘어납니다. 가용 가능한 노드들끼리 세션을 분산시켜 놓으면, 특정 노드가 갑자기 사용을 못하게 되더라도, 바로 다른 노드들에 분산이 되어서 운영 서비스에서 이용하는데 큰 문제가 없습니다.
생각보다 톰캣은 장애 대응을 위해 자체적으로 훌륭한 기능을 가지고 있습니다.
Clustering은 세션 정보들을 여러개의 노드에 잘 분산 관리하여 운영하는 방식입니다. 세션들을 백업하기도 하고, 복구하여 장애대응책도 있으니 좋은 방식입니다. 하지만 이 Tomat을 재기동 하는 과정에서 세션정보들이 유실 될 것이고, 그렇다면 배포 때마다 정보들은 초기화됩니다. 모든 Tomcat이 세션 정보를 가져야 하기 때문에 메모리 관리에 비효율적입니다. 이러한 현상을 예방하기 위해서는 별도의 저장소를 관리하는 것이 유리합니다. 마지막으로 외부 저장소를 이용하는 방법을 알아보겠습니다.
Session 외부 저장소로 Redis 사용하기 링크
https://escapefromcoding.tistory.com/702?category=1258162
'문제 해결, 기술 비교 > 개인프로젝트(북클럽)' 카테고리의 다른 글
| cache란? Redis를 cache로 조회 성능 개선하기 (0) | 2022.06.20 |
|---|---|
| Redis를 로그인 Session Storage로 이용하기 (0) | 2022.06.17 |
| sentry.io로 에러 로그 관리하기 (0) | 2022.06.01 |
| Elastic Search 연동 및 테스트하기 (0) | 2022.05.27 |
| RabbitMQ 이용해서 글 작성하기 (0) | 2022.05.27 |



