Entity 캐시
스프링 data jpa에서 제공하지 않거나 성능관련하여 직접 구현한다면 EntityManger를 사용해야 한다.
Hiberante에서는 EntityManager를 session이라고 불러서 구현하고 있다.
public void persist(Object entity);
public <T> T merge(T entity);
public void remove(Object entity);
public <T> T find(Class<T> entityClass, Object primaryKey);
public void flush();
우리가 save를 할 떄 실제 db에 저장하지 않는다. db에 들어갈 때에 gap이 존재한다. 그 공간이 영속성 컨텍스트이다.
영속성 컨텍스트에서 캐시처리를 jpa의 1차 캐시라고 말한다

1차 캐시는 map의 형태 [key= id값, value = 해당 엔티티]
id로 조회를 하면 영속성 컨텍스트에 존재하는 eneity가 있는지 확인, 있으면 db조회 없이 바로 조회한다.
만약에 1차 캐시에 Entity가 존재하지 않는다면, 영속성 컨텍스트 캐시에 저장하고 리턴한다
@Test
void cacheFindTest() {
System.out.println(userRepository.findByEmail("fastcampus@naver.com").get());
System.out.println(userRepository.findByEmail("fastcampus@naver.com").get());
System.out.println(userRepository.findByEmail("fastcampus@naver.com").get());
System.out.println(userRepository.findById(2L).get());
System.out.println(userRepository.findById(2L).get());
System.out.println(userRepository.findById(2L).get());
}*findByEmail 쿼리문
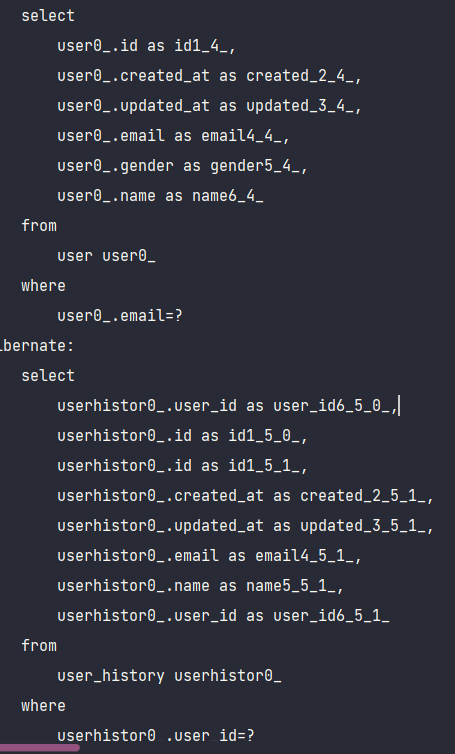


findByEmail()을 통해서 조회를 여러번 하면, 계속 쿼리문이 나간다. 왜냐하면 key값이 id로 조회하지 않기 때문에 영속성컨텍스트에 있어도 혜택이 없다.
*findById쿼리문

영속성 컨텍스트에서 key값인 id로 검색이 가능하기 때문에, 영속성 컨텍스트에 처음 조회문의 결과를 넣어주게되고 이후에 계속 호출은 영속성컨텍스트에서 한다.
@Test
void cacheFindTest2() {
User user = userRepository.findById(1L).get();
user.setName("berrrrrrrrrt");
userRepository.save(user);
user.setEmail("berrrrrrrrrt@naver.com");
userRepository.save(user);
}
@Transactional이 개별적으로 관리되기 때문에 update가 2번 나간다. save()메서드는 @Transactional을 가지고 있므로 cacheFindTest2()의 테스트는 각각 save에서 @Transactional이 적용된다.
@Test
@Transactional
void cacheFindTest2() {
User user = userRepository.findById(1L).get();
user.setName("berrrrrrrrrt");
userRepository.save(user);
user.setEmail("berrrrrrrrrt@naver.com");
userRepository.save(user);
entityManager.flush();
}
cacheFindTest2()에 @Transactional이 있다면, save() 2개가 @Transactional을 각각 가지고 처리하는 것이 아니라, cacheFind2Test()가 하나의 트랜잭션의 단위가 된다. 하지만, 현재 테스트코드이므로 모든것이 롤백되기 때문에 추가적으로 flush()를 사용해야 한다.
flush()를 하면, 모든 영속성 컨텍스트 내용을 끝까지 가지고 있다가 마지막에 한번에 반영하기 때문에 update가 한번만 나간다.
@Test
@Transactional
void cacheFindTest2() {
User user = userRepository.findById(1L).get();
user.setName("berrrrrrrrrt");
userRepository.save(user);
entityManager.flush();
user.setEmail("berrrrrrrrrt@naver.com");
userRepository.save(user);
entityManager.flush();
}
@Transactional의 경우 지연쓰기를 하기 때문에 최대한 나중에 처리를 반영한다.
flush()는 현재 영속성 컨텍스트를 반영하기 때문에, 처음 save() 건을 flush()로 반영하고, 이후에 save()로 flush()로 반영하여 각각 반영한다.
한가지 주의할 것은 flush()를 여러번 사용할 경우 쿼리 생성이 여러번 된다. User를 2번 save하면서 UserHistory도 각각 2번 save가 됐다. 딱히 필요한 상황이 아니라면, 영속성 컨텍스트 하나의 흐름 안에서 flush()를 한번만 사용하도록 한다.
@Test
@Transactional
void cacheFindTest2() {
User user = userRepository.findById(1L).get();
user.setName("berrrrrrrrrt");
userRepository.save(user);
//entityManager.flush();
user.setEmail("berrrrrrrrrt@naver.com");
userRepository.save(user);
//entityManager.flush();
System.out.println(userRepository.findById(1L));
}

@Transactional이 테스트코드에서 마지막에 커밋을 하지 않고, 롤백이 되기 때문에 따로 update 쿼리가 나가지 않는다.
@Test
@Transactional
void cacheFindTest2() {
User user = userRepository.findById(1L).get();
user.setName("berrrrrrrrrt");
userRepository.save(user);
//entityManager.flush();
user.setEmail("berrrrrrrrrt@naver.com");
userRepository.save(user);
//entityManager.flush();
System.out.println(userRepository.findAll());
}
아이디가 1L인 유저를 호출해서 수정했으며, 이후 findAll()을 통해 모든 것을 조회하고 있다. 아이디가 1L인 유저는 이름과 이메일이 바뀌었기 때문에 findAll()을 실행하면 반영된 부분을 DB에 저장하는 update문이 실행되게 된다.
이후 select * from User; 쿼리를 통해서 userRepository.findAll()을 실행한다.