개요
회사에서 사용하는 기존 통계 쿼리가 5개의 UNION으로 연결되어 있었습니다. 중복되는 코드가 엄청 많았고 약 150줄이었습니다. COUNT, SUM 등을 이용하여 개선을 할 수 있다고 판단하여 UNION을 CASE WHEN THEN을 개선했습니다
문제상황
GROUP BY를 통해서 크게 3개의 덩어리를 합쳐야 했는데, 각 덩어리는 GIRO_PBLC_YN 칼럼 값에 따라서 2개로 나뉩니다. '총 건수'를 계산하는 쿼리문 하나와, '지로발행 안함' 전용 쿼리가 합쳐집니다.
쿼리는 아래와 같습니다.
SELECT REQ_DT,
FILE_NM,
CRE_DT,
MAX(TOT_CNT) TOT_CNT,
MAX(TOT_CNT_N) TOT_CNT_N,
MAX(TOT_REQ_AMT) TOT_REQ_AMT
FROM (SELECT GD.OFFR_DT AS REQ_DT /* 신청일자*/ ,
GD.FILE_NM AS FILE_NM /* 파일명*/ ,
GD.CRE_DT AS CRE_DT /* 생성일자*/ ,
COUNT(*) AS TOT_CNT /* 총건수*/ ,
0 AS TOT_CNT_N /* 발행제외건수*/ ,
SUM(GD.GIRO_SUM_AMT) AS TOT_REQ_AMT /* 총요청금액*/
FROM TB_GIRO_D GD /* 청구내역*/
WHERE 1=1
AND GD.OFFR_DT BETWEEN #{REQ_DT1} AND #{REQ_DT2} /* 제공일자(발송예정일자)*/
GROUP BY GD.OFFR_DT /* 신청일자*/ ,
GD.FILE_NM /* 파일명*/ ,
GD.CRE_DT /* 생성일자*/
UNION
SELECT GD.OFFR_DT AS REQ_DT /* 신청일자*/ ,
GD.FILE_NM AS FILE_NM /* 파일명*/ ,
GD.CRE_DT AS CRE_DT /* 생성일자*/ ,
0 AS TOT_CNT /* 총건수*/ ,
COUNT(*) AS TOT_CNT_N /* 발행제외건수*/ ,
0 AS TOT_REQ_AMT /* 총요청금액*/
FROM TB_GIRO_D GD /* 청구내역*/ ,
TB_STLM_INF SI /* 결제정보*/
WHERE 1=1
AND GD.ORD_NO=SI.ORD_NO
AND GD.OFFR_DT BETWEEN #{REQ_DT1} AND #{REQ_DT2} /* 제공일자(발송예정일자)*/
AND SI.GIRO_PBLC_YN='N'
GROUP BY GD.OFFR_DT /* 신청일자*/ ,
GD.FILE_NM /* 파일명*/ ,
GD.CRE_DT /* 생성일자*/ )
GROUP BY REQ_DT,
FILE_NM,
CRE_DT
실행 계획은 아래와 같습니다. HASH 조인 2번을 사용하여 UNION-ALL을 합니다. 총 비용은 14입니다.

CASE WHEN THEN으로 개선하기
CASE WHEN THEN을 SUM으로 감싸서 특정 케이스에만 계속 1을 증가시키도록 합니다. GIRO_PBLC_YN = 'N'의 경우이기 때문에 해당 경우에만 1을 증가시키도록 하고 나머지 코드를 유지시키면 결과가 똑같이 나옵니다.
SELECT
GD.OFFR_DT AS REQ_DT /* 신청일자*/ ,
GD.FILE_NM AS FILE_NM /* 파일명*/ ,
GD.CRE_DT AS CRE_DT /* 생성일자*/ ,
COUNT(*) AS TOT_CNT /* 총건수*/ , ,
SUM(CASE WHEN SI.GIRO_PBLC_YN = 'N' THEN 1 END) AS TOT_CNT_N /* 발행제외건수*/ ,
0 AS TOT_REQ_AMT /* 총요청금액*/
FROM TB_GIRO_D GD /* 청구내역*/ ,
TB_STLM_INF SI /* 결제정보*/
WHERE 1=1
AND GD.ORD_NO=SI.ORD_NO
AND GD.OFFR_DT BETWEEN #{REQ_DT1} AND #{REQ_DT2} /* 제공일자(발송예정일자)*/
GROUP BY GD.OFFR_DT /* 신청일자*/ ,
GD.FILE_NM /* 파일명*/ ,
GD.CRE_DT /* 생성일자*/
중복되는 SELECT, FROM, WHERE절이 하나로 통합되었기 때문에 코드의 양이 줄었으며 마찬가지로 성능도 좋아졌습니다. 비용은 14에서 7로 줄었고 120Bytes 공간 사용에서 62 Bytes 공간을 사용합니다. SELECT 절에 분기를 하는 것이 WHERE절에서 조건을 거는 방법과 거의 같은 실행 계획을 가집니다.
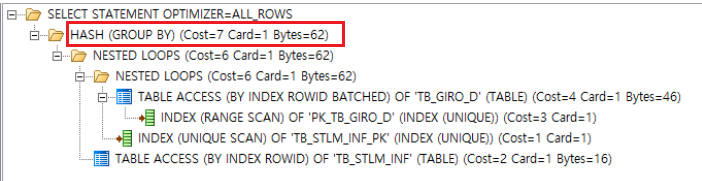
WHERE절에 제공일자 BETWEEN으로 NESTED LOOPS에서 (BY INDEX ROWID)를 사용하고, GROUP BY에 사용되는 3개의 칼럼은 PK이므로 INDEX가 (UNIQUE SCAN)으로 사용됩니다. 이는 기존에 2번 테이블으 접근하고 UNION-ALL을 한 것에 비해 훨씬 적은 비용과 공간을 활용하여 같은 결과를 출력합니다.
UNION의 단점
UNION으로 레코드 집합을 간단하게 합칠 수 있으므로 굉장히 편리합니다. 따라서 UNION으로 조건분기를 합니다. 하지만 SELECT 구문 전체를 여러 번 사용하는 것은 쓸데 없이 코드를 길게 만들며 테이블 접근이 늘어나고 저장소 I/O 비용이 증가합니다. 조건 분기는 가능하면 SELECT절에서 합니다(WHERE절에서 조건분기 하는 것보다 좋습니다!!!)
위의 결과에서 UNION을 사용하면 테이블 접근을 2번을 하지만, SELECT에서 조건분기를 하면 테이블 접근을 1번만 합니다. UNION, WHERE에서 조건 분기 하지 않고 꼭 SELECT에서 하도록 합니다!
참고
https://www.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS8208581587
'문제 해결, 기술 비교 > 실무 업무 회고' 카테고리의 다른 글
| 물류 재고 관리 개선하기 (0) | 2023.01.16 |
|---|---|
| 기존 로그를 스프링 AOP 로 개선하기 (0) | 2023.01.11 |
| 할인 쿠폰 개선하기 (0) | 2022.12.28 |
| 수기 업로드 작업 자동화 및 이메일 솔루션 사용 (0) | 2022.12.16 |
| NICE API 일시불 취소 개발하기 (0) | 2022.12.09 |



