Artillery는 사용하기 쉬운 성능 테스트 도구입니다.
높은 부하에서도 성능과 탄력성을 유지하는 확장 가능한 애플리케이션을 제공하는 데 사용합니다.
Artillery는 API 서비스, 전자 상거래 백엔드, 채팅 시스템, 게임 백엔드, 데이터베이스, 메시지 브로커 및 대기열,
그리고 네트워크를 통해 통신할 수 있는 모든 것과 같은 백엔드 시스템을 테스트하도록 설계되었습니다.
설치 경로이자 공식 문서는 아래와 같습니다.
https://www.artillery.io/docs/guides/getting-started/installing-artillery
Installing Artillery CLI | Artillery
- How to install the Artillery CLI via npm
docs-nine-inky.vercel.app
설치 명령어는 다음과 같습니다.
npm install -g artillery@latest
설치가 완료되면 다음과 같이 실행합니다.
artillery dino
Artillery 테스트를 위해서 사전에 알아두면 유용한 몇가지가 있습니다.
Virtual user (VU) : 서비스 가상 유저이며, 시나리오를 나타내는 여러가지 수행을 하게 됩니다
웹을 테스트한다면, 어플리케이션을 사용하는 사람으로 이해할 수 있습니다. API 고객인 셈입니다.
파일의 구성은 크게 config와 senario입니다.
scenario에는 vu의 정의가 포함됩니다. config는 target, phases, payload, plugins 등이 설정됩니다.
target : 테스트 시스템의 endpoint로 IP 혹은 URL입니다.
phases : 특정 시간동안 Artillery가 얼마나 많은 vu를 생성할지 결정합니다. 예를 들어, 일반적인 성능 테스트로 warm-up, ramp-up, maximum load의 단계를 가집니다. 매초마다 새로운 vu 생성이 가능하며, 시간에 따라 점진적으로 vu가 증가하는 ramp-up이 있고, 특정 시간동안 고정된 vu 생성, 특정 시간동안 vu의 생성 방지 등을 설정할 수 있습니다.
몇가지 예시를 살펴보겠습니다.
config:
target: "https://staging.example.com"
phases:
- duration: 300
arrivalRate: 50
target에 URL이 있으며, phases를 통해 매 초마다 50명의 vu가 5분동안 생성됩니다.
config:
target: "https://staging.example.com"
phases:
- duration: 120
arrivalRate: 10
rampTo: 50
target에 URL이 있으며, phase를 통해 매 초마다 10명으로 시작해서 2분일 때는 50명의 vu까지 점진적으로 증가 생성됩니다.
config:
target: "https://staging.example.com"
phases:
- duration: 60
arrivalCount: 20
target에 URL이 있으며, 60초동안 총 20명의 vu를 생성합니다. ( 3초마다 1명의 vu가 생성됩니다)
이 Artillery를 이용해서 한 줄 게시판의 POST(저장) 및 GET(조회) 성능을 개선해 볼 예정입니다.
한줄 게시판을 등록하는 POST와 조회하는 GET 2가지를 살펴봅니다.
POST(저장)은 1. 단순 JPA 저장, 2. Rabbitmq를 통한 JPA 저장, 3. ES를 통한 저장입니다.
GET(조회)는 1. 단순 JPA 조회, 2. ES를 사용한 조회합니다.
저장을 위한 Artillery 실행 예제문입니다.
config:
target: "http://34.84.182.116"
phases:
- duration: 60
arrivalRate: 3
name: Warm up
- duration: 120
arrivalRate: 3
rampTo: 100
name: Ramp up load
- duration: 600
arrivalRate: 100
name: Sustained load
payload:
path: "ratings_test_1k.csv"
fields:
- "content"
scenarios:
- name: "just post content"
flow:
- post:
url: "/api/diaryRaw"
json:
content: "{{ content }}"
target에 nginx의 IP를 적습니다.
phase는 총 3개로 구성되는데, 매초마다 3명의 vu를 1분동안 생성하는 Warm up, 3명의 vu를 2분에 걸처 점진적으로 증가시켜 100명까지 생성하는 Ramp to load, 10분동안 매초 10명의 vu 생성을 유지하는 Sustained load입니다.
payload를 통해, 미리 만들어둔 csv 파일을 이용해 한 줄을 기준으로 content를 사용하도록 합니다.
senario에서는 /api/diaryRaw 경로에 post요청으로 json형태로 content를 보내 게시글을 생성합니다.
이 과정에서 instance의 갯수, ES의 shard 갯수를 유동적으로 변경시킬 예정입니다. 또한, VU(virtual user)도 임의로 변경하여 여러 테스트를 해 볼 예정입니다.
스트레스 테스트 실행 명령어입니다.
artillery.cmd run --output report.json cpu-test.yaml
생성된 json 파일을 시각화해 보여줍니다.
artillery.cmd report report.json
1. 순수 JPA
All virtual users finished
Summary report @ 19:58:10(+0900)
Scenarios launched: 66433
Scenarios completed: 41051
Requests completed: 41051
Mean response/sec: 79.69
Response time (msec):
min: 70.1
max: 81614.5
median: 86.5
p95: 60104.2
p99: 67472.8
Scenario counts:
just post content: 66433 (100%)
Codes:
201: 2976
500: 2283
502: 29820
504: 5972
Errors:
ECONNRESET: 22578
ETIMEDOUT: 2797
ESOCKETTIMEDOUT: 7
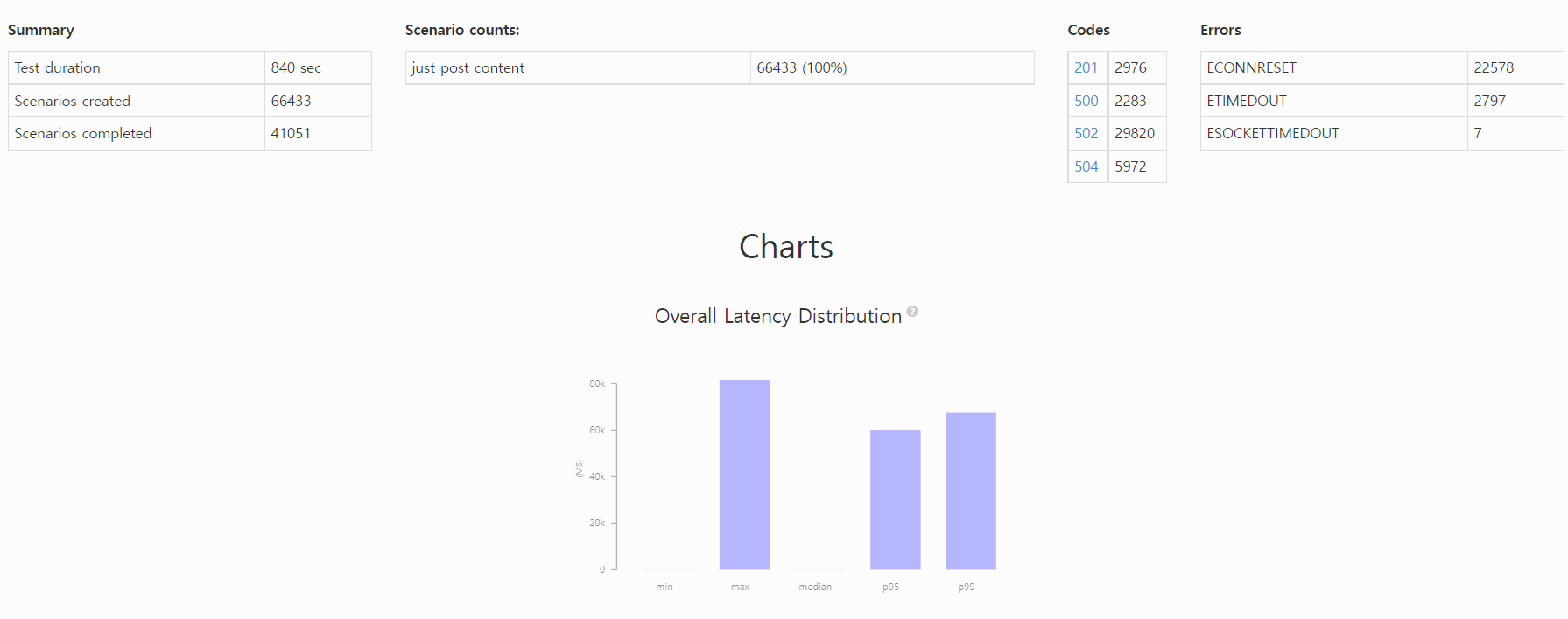


본격적으로 vu가 증가하는 200초를 기준으로 엄청난 부하가 걸리면서 많은 요청이 실패했습니다. 성공보다는 대부분 실패하였고, 엄청난 작업요청에 자원이 고갈되면서 연쇄적으로 실패했습니다.
2. RabbitMQ + JPA
All virtual users finished
Summary report @ 20:21:06(+0900)
Scenarios launched: 66325
Scenarios completed: 66325
Requests completed: 66325
Mean response/sec: 84.93
Response time (msec):
min: 87.4
max: 1499.1
median: 100.9
p95: 156.7
p99: 325
Scenario counts:
just post content: 66325 (100%)
Codes:
201: 66325



RabbitMQ의 Producer, Consumer 구조를 활용하여 개선하였더니 약 6만 6천개의 모든 요청을 성공하였습니다. DB I/O의 문제였기 때문에 scale-up, scale-out 형식이 아닌 DB접근을 최적화했습니다.
3. ES shard 1

All virtual users finished
Summary report @ 20:52:51(+0900)
Scenarios launched: 66339
Scenarios completed: 66339
Requests completed: 66339
Mean response/sec: 81.12
Response time (msec):
min: 87.1
max: 60155.4
median: 100.8
p95: 149.7
p99: 214.3
Scenario counts:
just post content: 66339 (100%)
Codes:
201: 66339
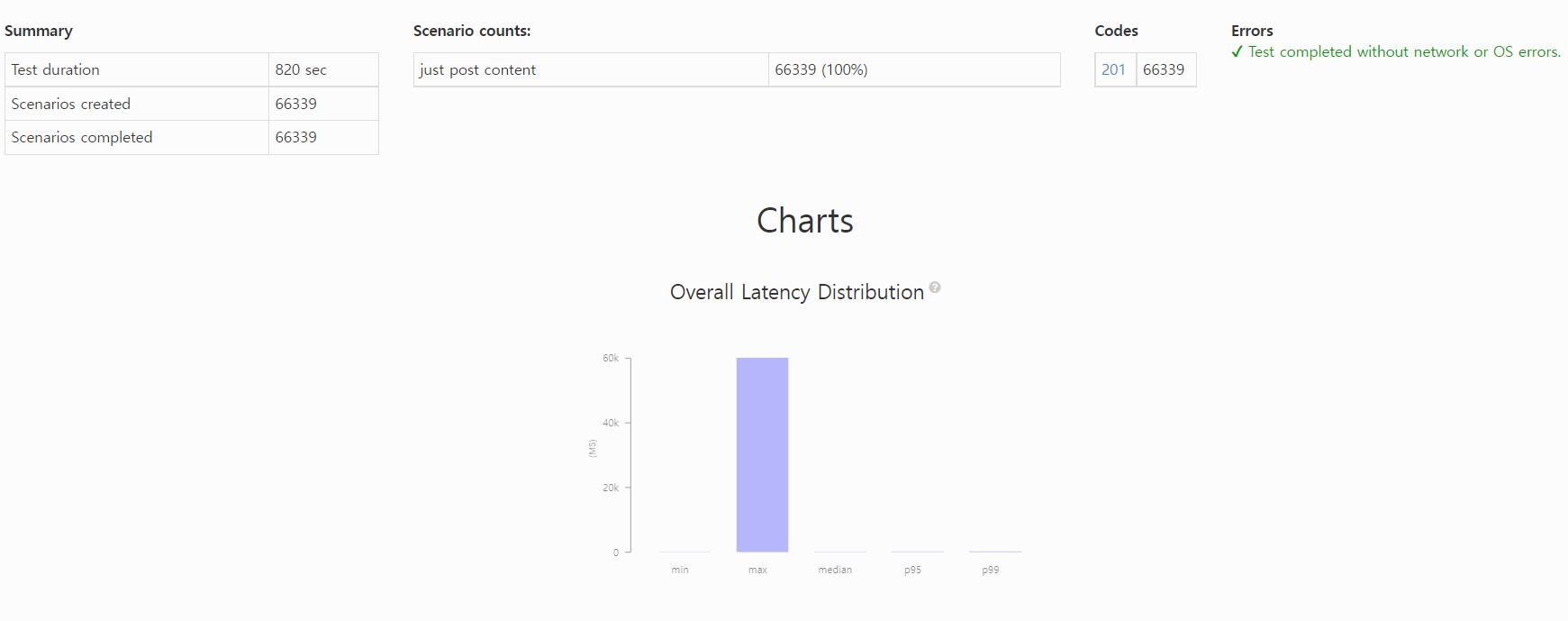


Elastic Search를 사용하도록 개선했습니다. 기존의 RDBMS 저장소가 아닌 엘라스틱 서치 전용 저장소를 사용했습니다. 1개만의 샤드를 사용했는데 모두 요청이 성공했으며, 응답속도가 많이 개선되었습니다.
4. ES shard 8

ummary report @ 21:24:49(+0900) 2022-06-14
Scenarios launched: 66376
Scenarios completed: 66376
Requests completed: 66376
Mean response/sec: 84.94
Response time (msec):
min: 86.5
max: 1275.9
median: 100.8
p95: 157.5
p99: 234.1
Scenario counts:
just post content: 66376 (100%)
Codes:
201: 66375
502: 1
Log file: es-8-instance-4.json

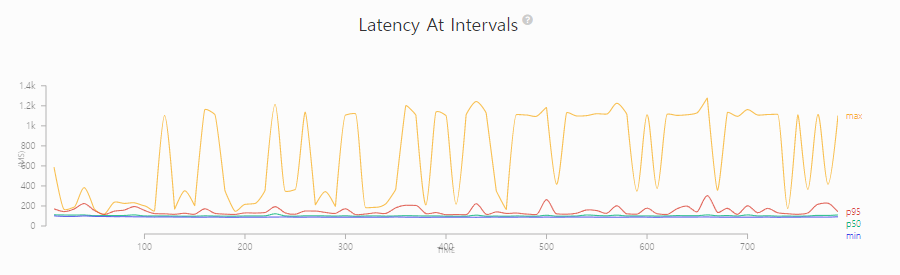
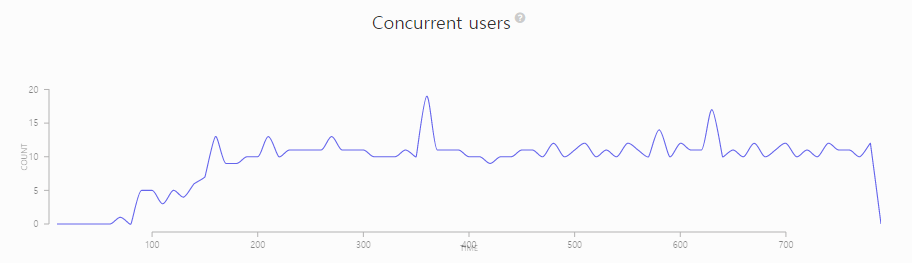
샤드를 8개로 늘렸는데, 이론적으로 모두 성공하는 것은 당연합니다.(샤드1개 일 때 모두 성공했기 때문, 1개의 오류가 나긴했다..!) 마찬가지로 대부분의 응답속도가 굉장히 고르고 안정적으로 분포되어 있습니다.
5. ES shard 8 + replica 1

All virtual users finished
Summary report @ 01:14:26(+0900)
Scenarios launched: 66340
Scenarios completed: 66313
Requests completed: 66313
Mean response/sec: 79.42
Response time (msec):
min: 140.7
max: 61223.4
median: 195.6
p95: 1187
p99: 1380.8
Scenario counts:
just post content: 66340 (100%)
Codes:
201: 66020
502: 38
504: 255
Errors:
ESOCKETTIMEDOUT: 26
ETIMEDOUT: 1



샤드 8개에 1개의 복제본 replica를 추가헀는데, 의외로 약 300개의 실패가 났습니다. 이는 초반의 가파른 요청에 따른 결과가 아닌가 생각해봅니다. 하지만 이후에는 안정적으로 처리했습니다.
* 글쓰기 저장 응답속도(단위 ms)
| 유형 | min | max | median | p95 | p99 |
| 순수 JPA | 70 | 8164 | 86 | 60104 | 67472 |
| RabbitMQ + JPA | 87 | 1499 | 100 | 156 | 325 |
| ES shard 1 | 87 | 60155 | 100 | 149 | 214 |
| ES shard 8 | 86 | 1275 | 100 | 157 | 234 |
| ES shard 8 + rep 1 | 140 | 61223 | 195 | 1187 | 1380 |
min : 가장 적은 응답시간
max : 가장 빠른 응답시간
median : 중앙값. 응답 시간 목록을 가지고 가장 빠른 시간부터 제일 느린 시간까지 정렬하면 중간 지점이 중앙값이다. 예를 들어, 중간 응답시간이 200ms이면, 요청의 반은 200ms 미만으로 반환되고 나머지 반은 그보다 오래 걸린다.(p50)
p95 : 요청의 95%가 특정 기준치보다 더 빠르면 해당 특정 기준치가 각 백분위의 응답 시간 기준치가 된다. 예를 들어, 95분위 응답 시간이 1.5초로마녀 100개의 요청 중 95개는 1.5초 미만이고, 100개의 요청 중 5개는 1.5초보다 오래 걸린다.
p99 : p95와 같은 개념으로 95%만 99%바꾸어서 해석하면 된다.
(데이터 중심 애플리케이션 설계 참고)
최소 응답속도는 모두 비슷하며, 최대 응답속도는 ES를 이용했을 때 가끔씩 튀는 것을 확인 할 수 있습니다.
RabbitMQ를 이용하여 글쓰기를 저장하는 경우에는 성능이 개선됩니다. ES는 검색에서 효과를 발휘하기 때문에, POST시에는 큰 차이는 없습니다. 그와중에 replica를 추가 한 경우, 데이터의 안정성을 위해 별도의 작업이 추가되기 때문에 응답속도가 조금 느려진 것을 확인 할 수 있습니다.
* 글쓰기 저장 응답결과
| 유형 | 201 | 500 | 502 | 504 | Error |
| 순수 JPA | 2976 | 2283 | 29820 | 5972 | 25382 |
| RabbitMQ + JPA | 66325 | ||||
| RabbitMQ + ES shard 1 | 66339 | ||||
| RabbitMQ + ES shard 8 | 66375 | 1 | |||
| RabbitMQ + Es shard 8 + replica 1 | 66020 | 38 | 255 |
(201 Created, 500 Internal Server Error, 502 Bad Gateway, 503 Service Unavailable, 504 Gateway Timeout)
500 대 에러는 보통, 유효한 요청들이 처리될 수 없는 서버의 상태를 의미합니다.(500대 에러 차이점) 순수 JPA 테스트의 경우, 과부화된 작업 요청으로 자원이 고갈되어 더이상 처리가 불가능해지고 연쇄적으로 오류가 발생됐음을 알 수 있습니다.
RabbitMQ의 Producer, Consumer 구조를 사용하면, 대부분의 글쓰기 요청이 성공합니다. 바로 DB I/O로 접근하는 것보다, RabbitMQ같은 MQ를 사용했을 때, 훨씬 부하를 줄일 수 있습니다.
* 글조회 응답속도(단위 ms)
속도 계산을 조금 더 분명하게 하기 위해 약 250k의 document를 사용했습니다.
* ES shard 1(단위 ms)
| 키워드 | 1회차 | 2회차 | 3회차 | 4회차 | 회차 | 평균 |
| 영화 | 11441 | 13790 | 14279 | 14261 | 15168 | 13787(13.7초) |
| 스토리 | 8578 | 2526 | 1953 | 2071 | 2373 | 3500(3.5초) |
| 감동 | 1018 | 1442 | 1243 | 1255 | 1136 | 1218(1.2초) |
| 재미 | 1771 | 1649 | 1361 | 1561 | 1278 | 1524(1.5초) |
* ES shard 8(단위 ms)
| 키워드 | 1회차 | 2회차 | 3회차 | 4회차 | 회차 | 평균 |
| 영화 | 5562 | 9974 | 7659 | 7941 | 7882 | 7803(7.8초) |
| 스토리 | 6770 | 1206 | 1178 | 1673 | 1358 | 2437(2.4초) |
| 감동 | 1137 | 782 | 1117 | 1168 | 939 | 1028(1.0초) |
| 재미 | 1675 | 922 | 1162 | 1029 | 929 | 1143(1.1초) |
* ES shard 8 + replica 1(단위 ms)
| 키워드 | 1회차 | 2회차 | 3회차 | 4회차 | 회차 | 평균 |
| 영화 | 10897 | 10333 | 10317 | 9609 | 14481 | 11127(11.1초) |
| 스토리 | 1619 | 1524 | 1457 | 1356 | 2126 | 1616(1.6초) |
| 감동 | 1356 | 1181 | 948 | 1126 | 1258 | 1173(1.1초) |
| 재미 | 5208 | 1175 | 1123 | 1131 | 1167 | 1960(1.9초) |
- 검색어가 많은 경우에는 ES shard가 많을수록 확실하게 성능 효과가 있습니다.
- 검색어가 적은 경우에는 shard 갯수에 상관없이 비슷한 성능을 낼 수도 있습니다.
- replica를 추가한 경우에는 복사본 저장소도 관리하기 때문에, 없을 때보다 조금 더 성능이 떨어졌습니다.
해당 검색어가 많을수록 ES와 shard의 위력이 나옴을 확인했습니다. replica는 운영에서 필수이기 때문에 replica를 활용하는 경우를 집중해서 테스트해 볼 필요가 있습니다.
(document를 500k, 그 이상으로 증대시켜서 테스트 하면 또다른 결과를 낼 것입니다.)
'문제 해결, 기술 비교 > 개인프로젝트(북클럽)' 카테고리의 다른 글
| jenkins build시, slack 알람 연동하기 (0) | 2022.05.22 |
|---|---|
| centos에 redis 설치하기 (0) | 2022.05.19 |
| 개인 프로젝트 오류 해결 (0) | 2022.05.13 |
| Github webhook & Jenkins 연동하기 (0) | 2022.02.05 |
| nginx를 이용한 로드밸런싱 및 무중단 배포 (0) | 2022.02.03 |



