개요
C, C++ 등의 언어는 메모리 관리를 위해 프로그래머가 객체의 생성뿐 아니라 삭제도 해야 합니다. 하지만, 가끔 삭제를 제대로 하지 않으면 새로운 객체가 생성될 메모리가 적어지고 OutOfMemoryErrors 오류가 납니다. 자바에서는 자동적으로 객체의 메모리 점유를 초기화(free)해주는 Garbage Collector가 존재합니다. 개발자가 직접 할당된 객체의 메모리를 제거하지 않기 때문에 좀 더 코드 구현에 집중할 수 있습니다. 삭제 알고리즘은 다양하며, 객체에 다양한 reference 수준을 설정하여 좀 더 최적화된 GC를 사용할 수 있습니다. 이번 글에서 GC가 어떻게 동작하여 객체를 삭제하는지 알아보겠습니다.
목차
가비지 컬렉터란?
Reference Counting Algorithm
Mark-and-Sweep Algorithm(Tracing)
Mark-Sweep-Compaction Algorithm
Stop and Copy Algorithm
Generatinal Algorithm
가비지 컬렉터란?
가비지 컬렉터(garbage collector)는 자동 메모리 관리 시스템입니다. 프로그램에 의해 할당된 메모리가 더이상 인스턴스를 참조하지 않아 가비지(garbage) 상태가 되면 자동으로 메모리를 초기화합니다.
아래 그림에서 왼쪽 파란색 네모는 스택(stack) 영역이고, 오른쪽 파란색 구름은 힙(heap) 영역입니다. 스택의 클래스 참조변수가 힙 메모리에 있는 인스턴스를 참조하고 있는 그림입니다. 빨간색으로 표시된 네모 객체들은 가비지 컬렉터의 제거대상입니다.
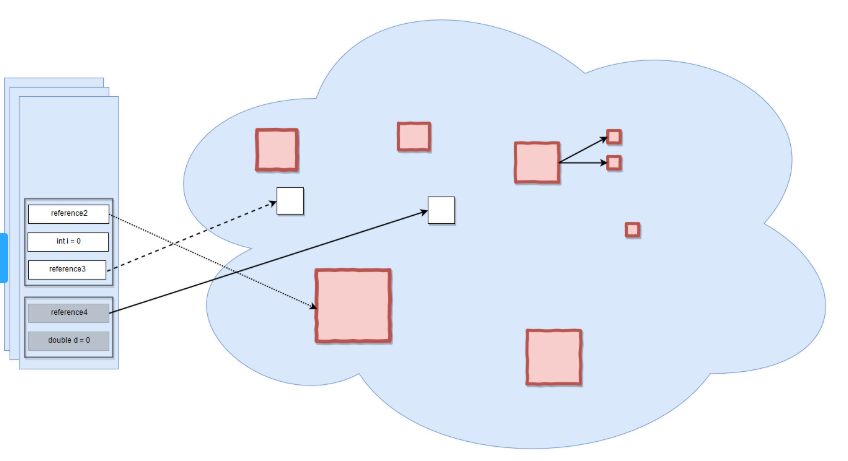
가비지 컬렉터는 다음 2가지 특징이 있습니다.
- 가비지 컬렉터 동작은 자바에 의해 자동 실행되고 어느 시점에 어디에서 시작할지에 따라 다르다.
- 가비지 컬렉터가 동작하면, 어플리케이션에 있는 모든 쓰레드들은 잠시 중단된다.
자바는 자체적으로 가비지 컬렉터를 관리하고 실행하지만, 개발자는 명시적으로 System.gc()를 통해 가비지 컬렉터가 실행하도록 조작할 수 있습니다. 하지만 직접 호출은 피해야 합니다. 가비지 컬렉터 과정 자체가 무거운 과정이기 때문에 다른 수행에 큰 영향을 미칠 수 있기 때문입니다. 따라서 직접 호출보다는 어떻게 동작할지 미리 설정하는 것을 권고합니다. 가비지 컬렉터는 다양한 방식의 알고리즘이 있습니다.
1. Reference Counting Algorithm
객체는 자신의 참조 횟수를 count로 기록합니다. count가 0이면 가비지(garbage)로 판단합니다. 참조할 때 객체의 count 값이 1 증가하고 참조가 끝나면 count 값이 1 내려갑니다. count가 0이 되면 객체의 메모리가 초기화됩니다. Tracing Garbage Collection과 달리 마지막 참조가 끝나는 순간 바로 객체가 소멸됩니다.
아래 코드로 예제를 확인하겠습니다.
Example:
Object p = new Integer(57);
Object q = new Integer(99);
p=q;
if(p!=q){
if(p!=null)
p.refCount--;
p=q;
if(p!=null)
p.refCount++;
}
아래 사진은 처음 객체 p, q 가 생성되고 p=q; 로 q가 참조하는 인스턴스를 p도 참조하도록 했을 때의 메모리 그림입니다.

초기에는 p와 q는 각각 57 ,99를 가리키고 있으므로 refCount=1입니다. p=q에 따라서 57을 가리키고 있던 p가 q가 가리키는 99로 바뀌면서 refCount가 1증가해 2가 됩니다. 이 알고리즘의 장점은 refCount를 통해 가비지를 구분하는 것이 편하고 즉각적으로 저장소의 갱신이 가능하다는 것입니다. 하지만 단점은 참조하는 객체가 많아질수록 계속 overhead가 늘어나고 reCount를 위한 별도의 공간을 할당해야 하므로 추가 공간이 필요합니다. 특히 Circular, Singly-LinkedList 같은 순환의 경우에는 치명적인 오류가 발생합니다. 실제로 사용하지 않더라도 순환참조 때문에 refCount=1 이어서 가비지 컬렉터가 사용하지 않는 객체를 삭제하지 않습니다.
아래 사진은 단일 순환 링크드 리스트입니다. 그림이 2개가 있는데 head 참조유무에 따른 refCount 값을 비교해보겠습니다.

상단의 그림은 head가 맨 왼쪽의 첫 번째 item을 참조하여 refCount=1입니다. 그리고 맨 오른쪽에 있는 마지막 item이 맨 처음 item을 참조하기 때문에 1이 증가해 refCount=2이 됩니다.
하단의 그림은 링크드 리스트 사용이 끝나서 head 참조를 제거한 이후입니다. head가 아무것도 참조하지 않음에도 불구하고 오른쪽 맨 마지막 item 때문에 아직도 맨 처음 item이 refCount=1로 남아있습니다. 따라서 GC는 계속 사용하는 객체로 인식하고 삭제하지 않습니다.
2. Mark-and-Sweep Algorithm(Tracing)
Mark 단계
Mark 단계는 루트(root) 노드가 힙(heap)에서 참조하는 객체들을 순회하면서 초기화 대상을 확인합니다. 루트는 객체를 참조하는 변수를 가리키며 지역변수를 통해 직접적으로 접근 가능합니다. 각 객체들은 mark bit을 가지고 있고 초기값은 0(false)입니다. 만약에 접근 가능한 객체(reachable objects)라면 bit가 1(true)로 설정됩니다.
Mark(root)
If markedBit(root) = false then
markedBit(root) = true
For each v referenced by root
Mark(v)
Sweep 단계
Sweep 단계는 가비지 컬렉터가 mark bit이 0(false)인 객체들을 초기화합니다. 이 객체들은 Mark 단계에 있지 않으므로 garbage 대상이 됩니다. 초기화 예정인 객체 리스트에 포함이 되어 추후 초기화가 되고, mark bit이 1(true)이었던 객체들은 다시 0(false)으로 설정됩니다.
Sweep()
For each object p in heap
If markedBit(p) = true then
markedBit(p) = false
else
heap.release(p)
아래 그림은 해당 알고리즘의 동작 방식입니다.

초기의 makred bit은 모두 0(false)입니다.

root에 따라서 접근 가능한 객체들(reachable objects)은 모두 1(true)로 바뀝니다.

가비지 컬렉터가 루트가 접근 불가능한 객체들(non reachable objects)은 제거하고 marked bit이 1(true)이였던 값들은 다시 모두 0(false)이 됩니다.
장점은 Reference Counting 알고리즘과 달리 순환에도 전혀 무한루프가 생성되지 않습니다. 또한 참조 count를 저장하고 변경할 때 추가적인 오버헤드가 발생하지 않습니다.
단점은 알고리즘이 작동하는 동안에 프로그램 실행이 지연되는 단점이 있습니다. 또한 알고리즘을 여러번 실행하고 난 후 사용하지 않은 메모리들이 중간중간 남게 되어 힙 메모리를 효과적으로 사용할 수 없는 단편화(fragmentation) 문제가 발생할 수 있습니다.
3. Mark-and-Compaction Algorithm

Mark-and-Compaction Algorithm은 Mark-and-Sweep 단계에서 Sweep 대신 Compaction을 사용해 객체들을 메모리 공간에 차곡차곡 쌓아 남는 공간이 발생하지 않도록 촘촘하게 관리합니다. Compactaction 과정에서 메모리를 재배열 할 때 순서를 정하는 3가지 방식이 있습니다.
Arbitrary - 빠른속도를 지향하며 원래 메모리에 있던 객체들의 순서와 관계없이 무작위로 정렬됩니다.
Linearising - 포인터, 참조, 형제자매 등의 관계있는 객체들이 모여 정렬됩니다.
Sliding - 힙에서 원래의 순서를 유지하며 할당 된 순서대로 정렬됩니다. (가장 빠른 compaction 알고리즘이고 많이 사용)
3가지 방법 중에 가장 빠르가 많이 사용하는 Sliding알고리즘을 알아보겠습니다. 내부적으로 Lisp2 알고리즘을 사용합니다.
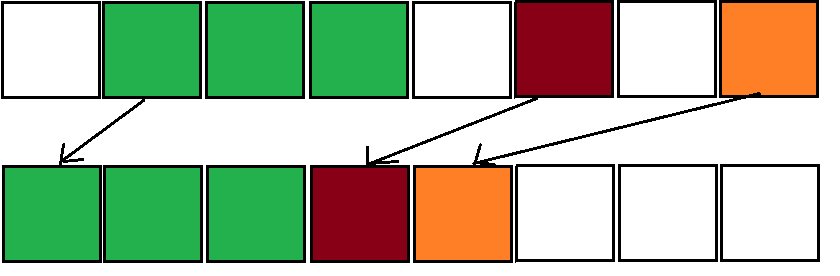
Lisp2 알고리즘은 각 객체에 추가적인 포인터 공간이 필요합니다. mark 이후 3가지 단계를 거칩니다.
1. 유효한 객체의 주소를 확인하고 계산합니다.
- free pointer, live pointer를 초기화하여 heap의 맨 처음을 가리키도록 합니다.
- live pointer가 유효한 객체를 가리키면 해당 객체의 forwarding pointer가 현재의 free pointer를 가리키게 하고 객체의 크기에 따라 free pointer의 값을 증가시킵니다.
2. pointer를 업데이트합니다.
각각의 객체에 대해 pointer들이 가리키고 있는 forwarding pointer에 따라 pointer를 갱신합니다.
3. 객체를 움직입니다.
각각의 객체에 대해 forwarding pointer가 가리키는 위치로 데이터를 움직입니다.
각 객체에 따라 forwarding pointer의 공간이 추가적으로 필요하지만 순서가 보존되고 단순하게 구현이 가능하며 성능적으로 가장 우수합니다.
이로써, Mark-and-Sweep보다 훨씬 효율적으로 힙 메모리를 관리할 수 있으며 단편화(fragmenataion)를 효과적으로 예방합니다. compaction 이후에도 매우 빠른 속도로 연속적인 할당이 가능하며 수명이 긴 객체의 경우에는 이동할 필요가 없습니다. 하지만 heap에서 3가지의 과정이 지속적으로 발생하므로 Mark-and-Sweep과 다음에 설명할 Stop-and-Copy에 비해 상대적으로 느립니다.
4. Stop-and-Copy Algorithm
Stop-and-Copy Algorithm은 힙을 두 공간으로 나누어, 메모리가 할당된 객체들은 항상 두 공간 중 하나의 공간에만 위치시킵니다. 반대 공간에는 아무것도 없이 비어있어야 합니다. 할당된 공간에 있는 메모리가 꽉 차면 프로그램이 잠시 지연되면서 가비지 컬렉터가 모든 객체들을 비어있는 공간으로 옮깁니다.
이제 두 공간의 역할을 바뀝니다. 할당된 객체들은 정렬된 순서대로 새로운 힙 공간에 복사가되고 단편화가 예방됩니다. 하지만 한쪽만 사용하기 때문에 힙 공간을 절반밖에 사용하지 못하며 가비지 컬렉터가 수행되는 동안 멈춰야 하며, 공간 이동시 객체들은 위치가 변경됩니다.(참조 정보가 계속 업데이트 되어야 합니다.)
아래 사진은 From Space의 공간이 꽉 찼기 떄문에 To Space로 객체들을 이동하는 과정입니다.

번개 모양은 참조가 없는 객체들로 소멸 될 객체들입니다. 이외에 갈색과 회색 객체들이 반대 공간으로 복사됩니다. From Space는 To Space로 바뀌어 사용되지 않는 빈 공간이 되었습니다. 비어 있었던 To Space은 From Space 공간이 되어 객체들이 저장됩니다. 정렬된 순서대로 빈 공간없이 객체들이 복사됩니다.
Mark and Sweep
Mark and Sweep은 Oracle사의 Hotspot JVM의 GC가 동작하는 방식이자 명칭입니다. Mark-and-Sweep 알고리즘과 이름과 비슷하지만 더 다양한 알고리즘이 사용되며 generational garbage collection 방식이라고 부릅니다. Mark and Sweep 알고리즘을 사용하는 것은 오랜 프로그래밍 경험을 바탕으로 효율적인 알고리즘들을 모아서 만든 것입니다. 자바는 stack의 변수들을 조사해서 계속 남아있어야 하는 객체들을 "mark"합니다. 제거해야 할 대상을 고를 것이라는 일반적인 통념과 반대됩니다. 그리고 사용하지 않는 객체들을 "sweep" 즉, 제거합니다.

Marking에서는 삭제될 객체와 남겨둘 객체를 구분하고, Normal Deletion에서는 객체를 삭제하며, 그 이후 Compacring을 통해 비어 있는 공간들을 그대로 냅두지 않고 객체들로 메꾼다.

Java 프로그램이 진행됨에 따라 GC에 의해서 시간이 지날수록 메모리가 할당되어 있는 객체들은 적어집니다. 이를 통해서 대부분의 객체들은 수명이 짧다는 것을 알 수 있습니다. 이러한 GC과정을 더 최적화 하기 위해서 heap 메모리를 좀 더 세분화해서 관리하게 됩니다. 왼쪽 상단에 위치한 Minor collections는 Young영역에서 발생하고 오른쪽 상단에 위치한 Major collectios는 Old영역에서 발생합니다. 결과를 바탕으로 다시 처음으로 돌아가 이 알고리즘은 2가지를 전제로 만들어 졌습니다.
1. 대부분은 unreachable 객체들이 되어 빠르게 소멸한다.
2. Old Generation에 있는 객체들이 Young Generation에 있는 객체를 참조할 확률은 희박하다.
heap 영역은 크게 Young Generation, Old Generation, Permanent Generation 3가지로 나뉩니다.
(경우 따라서 Permanent를 heap에 포함시키지 않기도 한다.)

Young Generation
최대 힙 영역의 약 40%를 차지합니다. 다시 eden과 2개의 Survivor Space로 나뉘어집니다.
Eden
2개의 Suvivor Space를 합친 영역보다 더 큰 공간을 차지합니다. 초기의 객체는 heap의 Eden 영역에 객체가 만들어지며 Eden이 꽉 차면 minor GC가 동작합니다. 대부분의 객체가 여기서 죽고 메모리가 초기화(free)됩니다. major GC와 비교하여 매우 빈번하게 발생합니다. minor GC 이후 살아남은 객체들은 Survivor Space로 이동합니다.
Survivor Space
eden에서 minor GC로부터 살아남은 객체들이 저장되는 장소입니다.. 2개인 이유는 메모리 단편화(Memory Fragmentation)을 방지하기 위해서 입니다. GC에 의해 객체가 생성되고 메모리 중간중간에 빈 공간들이 생기는데 이 때 공간들을 밀착(Compaction)시켜야 합니다. 하지만 이 과정을 피하기 위해서 남은 객체들을 또다른 Survivor Space로 복사합니다.(※Old Generation에서 major GC는 밀착(Compaction)을 통해 공간을 확보합니다.) ping-pong 형식으로 계속 객체들을 주고받으며 크게 다음과 같은 상황에서 Old Gernation으로 이동합니다.
1. 더 이상 초기화(free)되지 않다고 여겨질 만큼의 충분한 시간이 지났을 때
(GC가 발생할 때마다 age라는 메타정보가 증가되는데 어느순간 임계값을 넘어갈 때)
2. 새롭게 만들어진 객체들을 더 이상 공간이 부족해 Survivor Space에 저장되기 못할 때
Old Generation
Old Generation 또한 공간이 가득차면 Major GC를 실행됩니다. Major GC는 다양한 방식이 있습니다.
* 참고
https://www.geeksforgeeks.org/garbage-collection-java/
https://www.geeksforgeeks.org/mark-and-sweep-garbage-collection-algorithm/
https://stacktips.com/tutorials/se-concepts/reference-counting-garbage-collection
'학습' 카테고리의 다른 글
| JVM의 구조 (0) | 2022.10.21 |
|---|---|
| 가비지 컬렉터(Garbage Collector) - 2 (0) | 2022.10.18 |
| Array vs ArrayList (0) | 2022.10.17 |
| HashSet은 내부가 어떻게 구현이 되어 있는가? (0) | 2022.10.15 |
| ConcurrentHashMap vs Hashtable vs Synchronized Map (0) | 2022.10.15 |


